こうした特性は、作業負荷や認知負荷に直結し、開発生産性に影響を与える。この観点からの評価も、成果を正しく捉えるうえで欠かせない。
もし、理解しづらいコードを書いてしまったら、現在および将来の開発生産性が損なわれる。技術的負債とは、そうした “開発生産性の低下” を「利息を支払う」ことにたとえた概念だ。
本稿は、技術的負債を10のカテゴリに整理したGoogleの文献を参考にしつつ、技術的負債との付き合い方を考える。
技術的負債を10のカテゴリで捉える
エンジニアは、何を “技術的負債” だと感じているのだろうか。
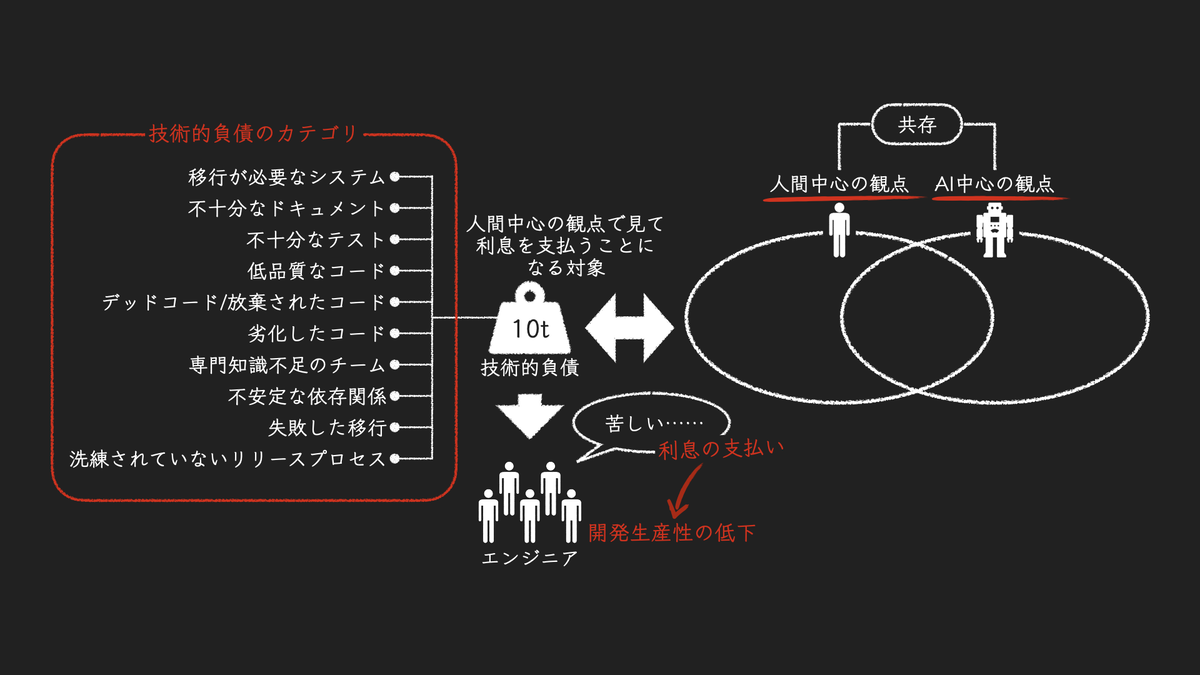
Googleは、社内調査を通して、それを10のカテゴリに分類した。その結果は、2023年4月に発表された次の文献にまとめられている。
参考文献: Ciera Jaspan and Collin Green, "Defining, Measuring, and Managing Technical Debt," in IEEE Software, vol. 40, no. 3, pp. 15-19, May-June 2023, doi: 10.1109/MS.2023.3242137.
こうしたカテゴリがあれば、チームや組織が抱える負債を可視化しやすくなり、管理も容易になる。どんなカテゴリに問題が集中しているのかが分かれば、チームや組織が抱える課題も鮮明になるだろう。
このように、技術的負債を分類する枠組みは、それ自体が実践的なヒントとなりうる。
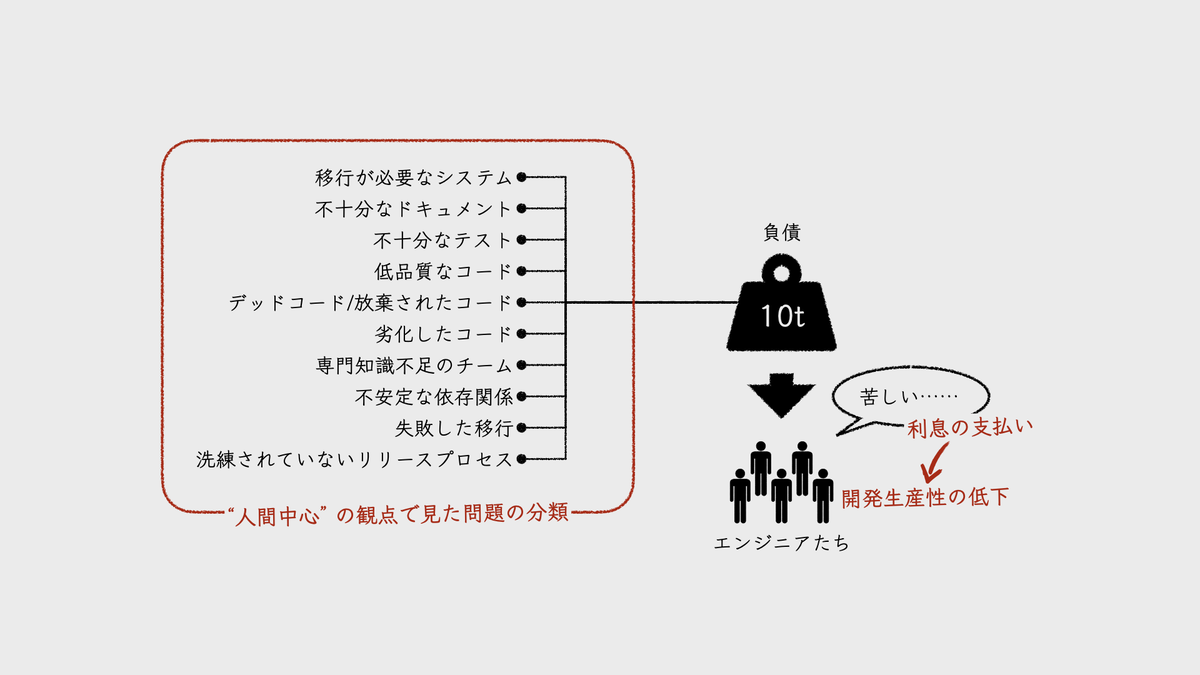
注意したいのは、負債とは、実際に「利息を支払った」あるいは「利息を支払う」対象である点だ。どれだけコードの品質が低くても、そのコードを誰も見ないなら、負債とは言えない。実際に、コードを読むことや変更することに苦労してはじめて “利息の支払い” が生じ、そこが負債となる。
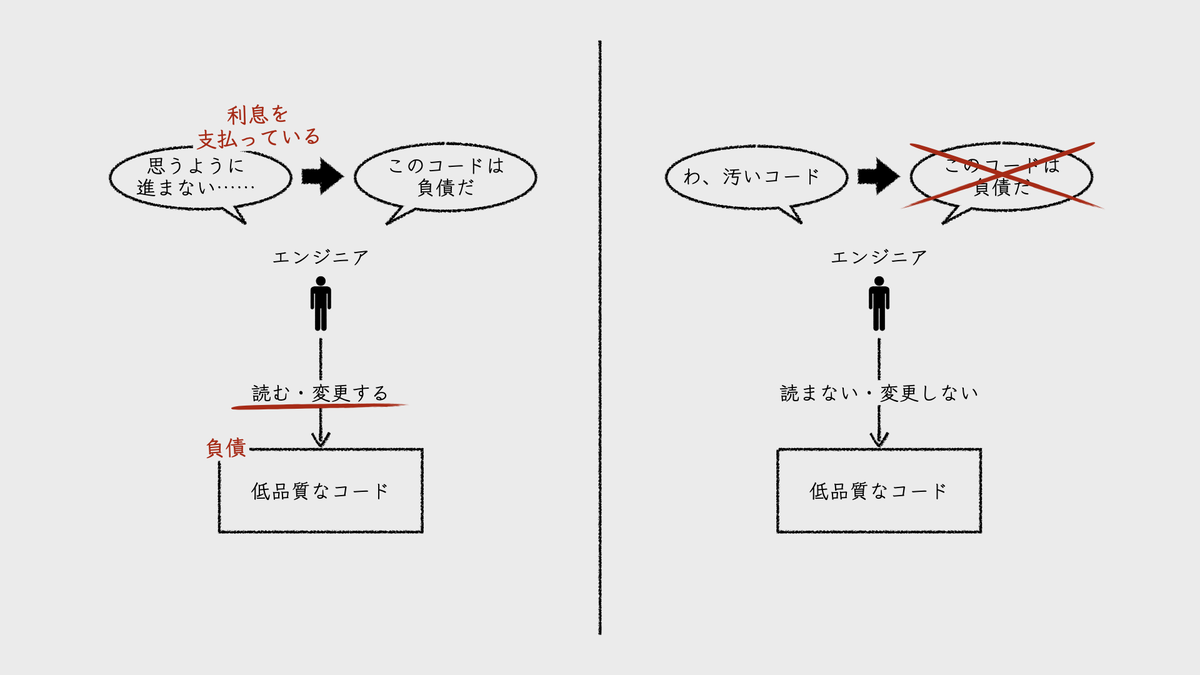
Google社内の調査でも、技術的負債のカテゴリ化にあたって、実際に「生産性の妨げとなった」ものをエンジニアに尋ねている。つまり、「どんな負債に遭遇したか」ではなく、“実際に利息を支払った対象” に焦点を当てている。
以降に挙げる10個が、そこで明らかになったカテゴリだ。
≫ 移行が必要なシステム
システム移行や技術スタックの更新に多くのリソースを割かれ、通常の開発業務が圧迫されている状態を指す。文献内では、たとえば、「スケーラビリティへの対応」「規制変更などへの対応」「依存関係の整理」「非推奨技術からの脱却」といった理由での移行が挙げられている。
Googleでは、このカテゴリが最も深刻な技術的負債とされている。
その背景には、同社がモノリシックなリポジトリを採用しているという特殊事情がある。リポジトリ全体にまたがる大規模な移行が、頻繁に実行されるためだ。
ただし、この問題は、モノリシックリポジトリを採用していない組織でも起こり得る。複数の開発組織を抱える企業では、共通で利用しているプラットフォームやライブラリの更新・移行への対応があるからだ。また、社内の開発ルール変更に対応する必要もあるだろう。
≫ 不十分なドキュメント
プロジェクトやAPIに関するドキュメントが存在しない、あるいは不完全な状態を指す。
必要な情報に辿り着けない状況も、これに含まれる。たとえば、社内Wikiが適切にメンテナンスされていなければ、新旧のドキュメントが混在して、どれが信頼できる情報なのか判断がつかない。また、検索しても、適切なドキュメントが見つからず、作業が滞ることもある。
≫ 不十分なテスト
テストの品質やカバレッジが低い状態を指す。テストケースが漏れていたり、テストデータが不適切な状況も含まれる。
結果として、事前に防げたかもしれない不具合が見過ごされ、余計な手戻りが発生しやすくなる。たとえば、埋め込んでしまった脆弱性の対応に追われたり、デプロイのロールバックを余儀なくされたりする。さらに、実行のたびに結果が変わるflakyなテストに悩まされることだってある。
≫ 低品質なコード
プロジェクトが生み出したアーキテクチャや設計、コードの品質が低く、主に保守性が損なわれている状態を指す。技術的負債という言葉から、真っ先に思い浮かべるのは、このカテゴリだろう。
こうした問題は、現在および将来の開発生産性の妨げになる。エンジニアの誰もが知る通り、コードを理解することに苦労したり、変更・拡張することに対する足かせとなるからだ。
文献内では、その原因として、「開発を急ぐこと」や「デモ版/プロトタイプ版の影響」が挙げられている。後者は、検証目的で作られた低品質なアーキテクチャや設計、コードが、プロダクション版に引き継がれてしまう状況を指しているのだろう。
≫ デッドコード/放棄されたコード
使われていないコードが削除されずに残されている状態を指す。
これはコード単位にとどまらず、機能やプロジェクト単位でも起こり得る。置き換えや廃止が行われたにも関わらず、古いコードが残されたままだと、エンジニアにとってはノイズとなり、認知負荷を高める。
プロジェクト単位で残されたコードが、なぜ邪魔になるのか、分かりにくいかもしれない。廃止されたプロジェクトのリポジトリなど、普段は誰も見ないからだ。そうであれば、邪魔になることなどなさそうに思える。
しかし、使われないリポジトリがコード管理システムに残り続けると、コード検索のノイズになってしまう。また、それが本当に使われていないのか判別できず、エンジニアが無駄に時間を費やすこともある。特に、Googleのようなモノリシックリポジトリなら、なおさらだろう。
≫ 劣化したコード
時間の経過とともに、品質が低下していったコードを指す。先述の「低品質なコード」とは異なり、当初は問題がなかったにもかかわらず、後から技術的負債へと変化していったものだ。
その背景には、大きく二つの原因がある。
その一つは、追加開発を繰り返すことだ。初期リリース時には想定していなかった機能追加や仕様変更を加えるうちに、内部構造には歪みが生じていく。場当たり的な修正も積み重なる。TODOやFIXMEが大量に残されたコードは、そうした兆候の一つだ。結果として、構造が複雑化し、柔軟性も失われていく。
もう一つの原因は、採用している技術や設計が、相対的に古くなることだ。依存関係にある外部ライブラリがEOLを迎えるケースは、その典型例だろう。
≫ 専門知識不足のチーム
チームが、コードベースやプロジェクトを適切に管理・開発し続けられない状態を指す。
たとえば、システムを引き継いだものの、十分に理解できないまま保守・運用するケースが挙げられる。原因はさまざまだ。引き継ぎが不十分だったのかもしれないし、メンバーの離脱によって属人化したコードが扱えなくなったのかもしれない。あるいは単に、人員が足りていないのかもしれない。
≫ 不安定な依存関係
依存しているライブラリやフレームワーク、外部サービスの動作が不安定だったり、頻繁に更新されたりする状態を指す。仕様の不整合が起きるケースも含まれる。
たとえば、依存サービスの動作が不安定だと、自チームのシステムがトラブルを起こし、緊急対応を余儀なくされることがある。バグの多いライブラリを使ってしまった場合も同様だ。
また、頻繁に更新されるライブラリを使っていると、その変化に追随するためのメンテナンスコストがかかる。旧バージョンのままでは、いずれサポートが終了するかもしれず、対応を迫られることになる。
更新に追いついても、仕様変更によって思わぬ不具合が生じ、結果としてロールバックせざるを得ないこともあるだろう。
≫ 失敗した移行
古いシステムから新しいシステムへの移行が完了しない状態を指す。ここでの「新旧」は、まったく異なる別システムの場合もあれば、同じコードベースの旧バージョンと新バージョンの場合もある。
移行が中途半端なままだと、複数のシステムやバージョンを同時にメンテナンスしなければならず、人的リソースを大きく消耗する。加えて、システム全体の複雑性も増し、保守や変更のハードルが上がっていく。こうした負担が、エンジニアの悩みの種になる。
≫ 洗練されていないリリースプロセス
本番環境へのデプロイ手順が複雑であったり、モニタリング環境が整備されていない状態を指す。これは、Ops領域に関する技術的負債である。
たとえば、継続的デリバリー/デプロイ(continuous delivery / continuous deployment)が整備されていなければ、本番反映のたびに手間と時間を要する。特に、頻繁なリリースが求められる現場では、その負担は致命的な問題になるだろう。
また、運用の自動化が進んでおらず、トイル(toil)にまみれているなら、日常的なルーチン作業に時間を奪われやすい。品質も安定しにくく、手戻りリスクも高まる。
こうした未整備な状態は、トラブル発生時の迅速な復旧を難しくし、信頼性の低下につながる恐れがある。
カテゴリを使った問題の可視化からはじめる
技術的負債への取り組みは、まず「何が問題か」を可視化するところから始まる。定量的であれ、定性的であれ、可視化できれば、問題の認識を皆で一致させやすくなる。
Googleの10のカテゴリは、その可視化に役立つ。自分たちの組織やチームでは、どのカテゴリに属する負債に悩まされているのか。たとえば、アンケートなどを通じて現場の声を集めれば、注力すべきカテゴリが見えてくる。そのうえで、何が具体的な障害になっているのかを深掘りできるだろう。
たとえば、「不十分なドキュメント」が一番の問題だと特定されたとしよう。それはチーム内のドキュメントの問題なのか、あるいは利用している社内プラットフォーム側の問題なのか。ドキュメントが不足しているのか、存在していても情報が埋もれて辿り着けないのか。
こうした問いを、組織やチームで丁寧に議論できるようになる。
対策には、目の前の問題に対処する “対処療法” 的な観点と、その原因を根本から見直す “原因療法” 的な観点の両方が必要だ。たとえば、ドキュメントが古いのであれば、まずはそれを更新する。そして、なぜ古いままで放置されるのかという根本原因にも向き合う。それは、ドキュメントの更新がプロセスに組み込まれていないといったことかもしれない。
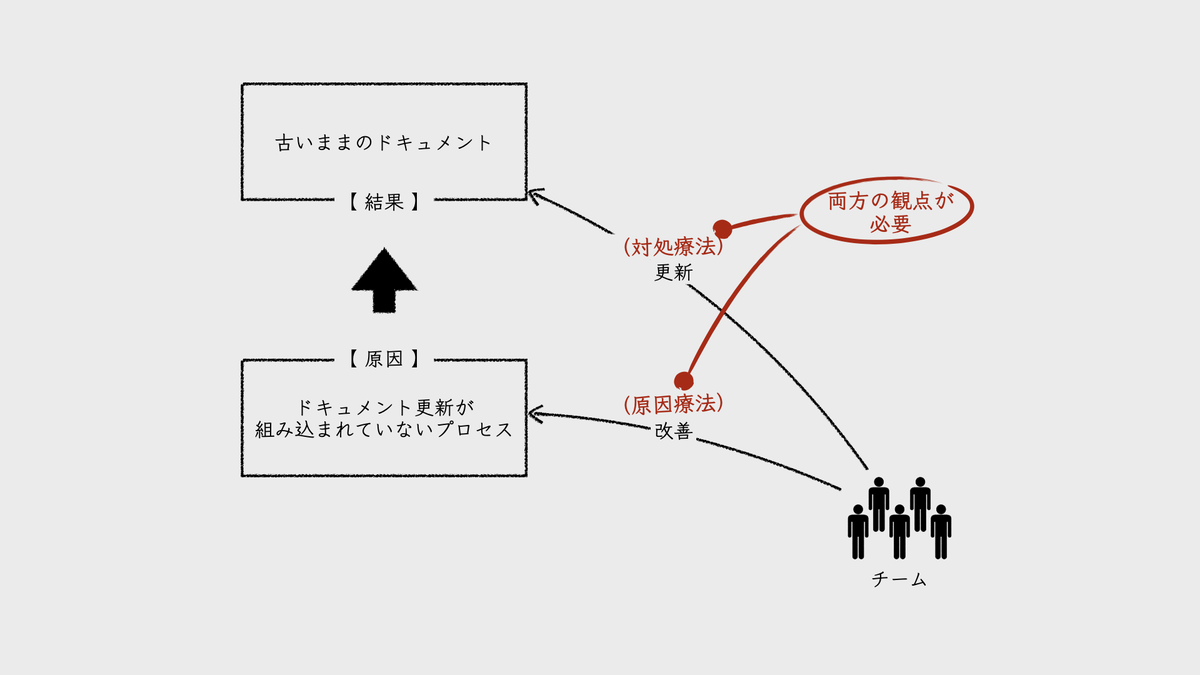
さらに、対策を進める中でチームが得た知見は、組織全体で標準化していくとよい。チーム内にとどまっていたローカルナレッジを、組織全体で再利用可能なグローバルナレッジへと展開するのだ。
文献からは、Google社内における技術的負債の管理方法が、次の4つのステップに整理できる。
- 問題の可視化
- 優先順位の明確化と計画化
- 根本原因の特定と対応
- 組織全体での標準化
これはまさに、個々のチームの取り組みを、組織全体の学びへと昇華させるプロセスである。
“人間中心” と “AI中心” が共存するソフトウェアエンジニアリングへ
人間中心設計(human-centered design, HCD)という言葉がある。ユーザーの特性を深く理解し、それに基づいてプロダクトやサービスをデザインするアプローチだ。
この考え方は、ユーザーに向けた外部品質だけでなく、エンジニアにとっての内部品質にも応用できる。ソフトウェアプロダクトを扱うならば、どちらの視点も欠かせない。
これまでのソフトウェアエンジニアリングは、人の営みであるという点で、その観点は “人間中心” である。だからこそ、エンジニアが扱いやすいコード、設計、アーキテクチャ、環境であって欲しい。それが欠ければ、開発生産性の低下を招く。
端的に言えば、エンジニアが苦しむ状況は、開発生産性の低下と直結しているのだ。
ウォード・カニンガムが作り出した「技術的負債」という概念は、まさに “人間中心” であり、エンジニアの認知的な負荷を強調したものだ。Googleの文献内でも、“人間中心” という言葉が使われている。
私は本稿の冒頭で、次のように述べた。
ソフトウェア開発の成果は、エンジニアの特性に大きく左右される。たとえば “コードを理解する能力” は、その代表的な要素だろう。エンジニアの作業負荷や認知負荷の視点での評価も必要だということだ。
しかし、生成AIの登場によって、この状況は変わりつつある。少なくとも、エンジニアが感じる認知負荷は、徐々に緩和され始めている。
特に、AIによるコード生成の精度は目覚ましく進化しており、エンジニアが直接コードを書く時間は確実に減ってきている。これにより、認知負荷の一部がAIによって肩代わりされるようになってきた。
その結果、AIの出力をより高品質にするために、環境整備への関心も高まっている。たとえば、リポジトリ内にドキュメントを整備し、AIが参照できる情報を増やす取り組みが進んでいる現場もある。
こうした動きは、“AI中心” のソフトウェアエンジニアリングの萌芽と言える。私たちは今、長らく続いた “人間中心” の時代から、“人間中心” と “AI中心” が共存するフェーズに入ったのだ。そして今後、その重心は徐々にAI側へと移っていくだろう。
だが、技術的負債の10のカテゴリを眺めると、現在のAIが得意とする領域と、そうでない領域があると分かる。まだまだ人間が介在しなければならない箇所も多い。
たとえば、「低品質なコード」や「劣化したコード」もそうだ。コード生成は、AIが得意とする領域である。コードを理解するのも、書くのもAIであるなら、品質はさほど問題にならない。そんな期待もあるだろう。だが、現実はそう単純ではない。
いまのところ、すべてのコードをAIが生成できるわけではない。人間がコードを読み、修正する場面は依然として存在する。特に、本番トラブルのような緊急時には、人がコードを正しく理解していなければ迅速な対応は難しい。
また、AIが生成したコードの品質が十分でないケースも珍しくない。それ自体が、エンジニアの新たな認知負荷となってしまうのだ。
いつかは、すべてをAIが担う時代が来るかもしれない。だが、少なくとも今はまだ、その時ではない。
人間中心とAI中心の共存・両立を目指すのが、今のところの現実解なのだろう。