“他者から頼られる”というのも、優れたエンジニアの一つの表れ方だろう。
たとえば、困っているといつも助けてくれる人。難易度の高い問題を解決してくれる人。チームや組織の能力を引き上げてくれる人。事業やプロジェクトの意思決定を技術面から支えてくれる人など。誰から、どのような場面で頼られているかは、それぞれ異なる。
彼らに一貫しているのは、扱うスコープこそ違えど、周囲にインパクトをもたらし、その結果として信頼を得ている点である。与えられた責務を着実に果たすだけでなく、周囲や組織にも貢献する人物だ。
それでは、彼らはどのようなスコープを担い、どのようなコンピテンシーを有しているのだろうか。そして、AI時代にそれはどう変わるのか。本記事では、他者から頼られるタイプの優れたエンジニアを6つに分類し、考察する。
なお、ここで扱う“優れたエンジニア”は、あくまでも“他者から頼られるタイプ”に限定している。優秀さそのものを網羅的に定義しようとしているわけではない。
本記事のAI音声解説版をポッドキャストで“準備中”
🎧ぜひ番組「FLOW(er)ラジオ」をフォローしてお待ちください!
- 他者から頼られるタイプの優れたエンジニアは、誰から何を頼られているのか
- エンジニアがもたらすインパクト = スコープ × コンピテンシー
- 6タイプのエンジニアが担うスコープを2軸で捉える
- 6タイプのエンジニアが発揮するコンピテンシーを6つの軸から捉える
- EMに頼られるエンジニアと、EMには共通点がある
- AI時代のエンジニアは何が変わり、何が変わらないのか
- 参考文献
他者から頼られるタイプの優れたエンジニアは、誰から何を頼られているのか
私がこれまで観察してきたなかで、優秀だと言われるエンジニアの多くは、成果を通じて周囲の信頼を獲得し、頼られる存在になっていた。もちろん、「頼られること」が優秀さのすべてではない。それでも、優秀さが周囲との関係に表れる一つの典型的な形であった。
そのため、本人と他者との関係性によって、評価の観点に違いが出る。それはそうだろう。優れたアーキテクチャを描いたところで、他職種のメンバーが「素晴らしい」と褒めてくれることなどない。そこで見られるのは、自分たちが抱える課題や目標にどう影響を与え、価値をもたらすかである。
つまり、優秀さは、純粋な「技術力の高さ」だけで評されるものではない。能力を成果へ結びつけ、関係する個人や組織・集団に対し、継続的に貢献した結果として、「頼られる」という関係にも表れるのだ。本記事では、そうした優秀さの表れ方に焦点を当てている。
そこで、エンジニアとの典型的な関係性に基づいて、評価の側面を6つに分類した。それぞれの立場から、どのような貢献が評価され、どのようなエンジニアが頼りになる存在と見なされるのか。私の観察に基づく主観的な整理であるが、順に見ていこう。
誤解しないで欲しいのだが、これらは互いに排他的な分類ではない。一人のエンジニアが、複数のタイプにまたがることもある。
① チーム内のエンジニアに頼られるエンジニア
チーム内で評価されるのは、チームの課題を解決し、日々の開発を前進させるエンジニアである。さらに、チームの仕事をより高い水準へと引き上げてくれる。
- 担当システムの構造や背景を深く理解しており、変更時の影響範囲を正確に見抜く。
- コード以外の技術レイヤーにも精通しており、インフラやミドルウェアが絡む複雑な障害の特定や、システム全体のチューニングを主導できる。
- 自分のタスクが行き詰まった時に、いつでも親身になって助けてくれる。
- 新しい技術や開発手法を、誰もが扱える仕組みに落とし込み、チームの開発効率や品質を高めてくれる。
- 設計や方針の議論において、他とは異なる視点や発想から意見を出し、その場にブレイクスルーをもたらしてくれる。
ここで求められるのは、突出した技術力や深い専門性だけではない。自らが得た知見を、皆で活用できる仕組みに変える力も評価される。物事を多角的に捉え、チームに新たな視点をもたらす力も重要だ。
こうした存在は、「このチームなら困難も乗り越えられる」という安心感を周囲にもたらす。日々共に働くなかで、その思考や仕事ぶりにも触れられるため、憧れの対象やロールモデルにもなりやすい。
② 社内他チームのエンジニアに頼られるエンジニア
チームの境界を越えた連携では、技術課題の解決をリードし、存在感を示すエンジニアが高い評価を得る。
- 複数チームが関わる複雑なアーキテクチャや設計を整理し、全体の方向性をリードしてくれる。
- チーム間での機能連携や共通開発を行う際、チーム外のコードであっても、その背景を深く理解したうえで、適切な変更を加えられる。
- 組織全体が扱う開発環境を改善・進化させ、全体の開発効率と品質を底上げしてくれる。
- 複数システムにまたがる障害でも、全体を俯瞰してチームを越えた調査を主導し、真の原因を迅速に突き止めてくれる。
ここで評価されるのは、複数のシステムやチームを横断して理解する力だ。自チームの担当領域だけに閉じず、関連するシステムや各チームの背景・制約まで捉える。その理解に基づいて、チーム間の依存関係を整理する。そして、全体最適の設計や共通の仕組みを形にし、問題を解決へと導いていく。
こうしたエンジニアは、チームの垣根を越えて頼られ、組織横断の技術的な相談役となっている。
③ エンジニアリングマネージャーに頼られるエンジニア
EMが頼るのは、チームを技術面でリードするだけでなく、判断の難しい局面で対等に意見を交わし、技術的な方向性を示してくれるエンジニアだ。
- たとえばレガシーシステムの刷新など、技術的な不確実性が高く困難なプロジェクトであっても安心して任せられ、自走して確実に解決まで導いてくれる。
- 判断の難しい技術的な局面でも、トレードオフを明確にしたうえで、進むべき現実的な方向性を示してくれる。
- 現場の頑張りや運用に依存していた課題に対し、自分の責務を越えた領域であっても自律的に解決策を検討し、的確な提案をしてくれる。
彼らは、自らが担う責務の範囲にとどまらず、より上位の課題にも遠慮なく踏み込む。高い技術力や問題解決力を持ちながら、俯瞰的な視点からチームや組織全体の課題にも関心を向けている。そうして、周囲やEMを巻き込みながら、技術や仕組みによって解決へ導いていく。
こうしたエンジニアは、EMにとって単なる一人のメンバーではない。技術面からチームを共に導くパートナーであり、「右腕」的存在である。
④ 他職種の社員に頼られるエンジニア
他職種のメンバーが頼りにするのは、ユーザーやビジネスの事情も踏まえて、現実的な解決策を一緒に考えられるエンジニアである。技術的な都合だけを一方的に押し付けたりはしない。
- 技術的な背景や仕組みを、専門知識がなくても理解できる言葉で分かりやすく説明してくれる。
- 単に「できる、できない」の回答にとどまらず、技術的な制約を踏まえたうえで、実現可能なアプローチや代替案を提案してくれる。
- 企画や仕様の検討段階において、技術的な観点から新たな気づきを与え、生み出すプロダクトの価値を高めてくれる。
彼らが果たすのは、技術と非技術の間をつなぐ役割だ。技術的な背景や制約をエンジニア以外にも理解できる言葉へ翻訳し、実現可能なアプローチや代替案を示す。さらに、企画や仕様の検討段階から技術的な観点を持ち込むことで、プロダクトの価値や意思決定の質を高める。
結果として、こうしたエンジニアの活躍が、組織内でのエンジニアリングのプレゼンスを高めている。エンジニアリングが、事業やプロダクトの価値を高める存在として認識されているのだ。
他職種の社員にとって、彼らは単なる実装の担い手ではない。サービスやプロダクトを共につくるパートナーとして信頼され、真っ先に相談を持ちかけられる存在である。
⑤ 経営者に頼られるエンジニア
経営者にとって、自社の技術的な状況を正しく伝え、経営の意思決定を支えてくれるエンジニアの存在は心強い。とりわけ、エンジニアとしての背景を持たない経営者にとって、彼らが果たす役割は大きい。
- 技術的な投資判断について相談でき、技術を事業成長につなげる方法を提案してくれる。
- 全社的な技術課題を構造的に整理し、目指す組織像と、そこへ至る技術戦略やロードマップを明確に示してくれる。
- 経営方針や事業戦略をエンジニアリングのコンテキストへ正しく翻訳し、目標達成に向けて組織の実行力を最大化してくれる。
彼らが担うのは、経営戦略を技術戦略と実行へつなぐ役割だ。技術面でのビジョンを示し、現状とのギャップを明らかにして、技術戦略とロードマップを描く。さらに、その実行を自らリードし、最後までやり切る。
その結果、技術組織や開発環境が整い、社内のエンジニアたちが能力を十分に発揮できるようになる。
技術面から経営の意思決定を支え、事業の方向性にも影響を与える。そこまで信頼されたエンジニアは、経営者の「右腕」*1と呼ばれるようになる。
⑥ 社外のエンジニアに頼られるエンジニア
彼らは、エンジニアが日々直面する課題に対して、解決策や新たな視点を継続的に提供する存在だ。組織の枠を越えて多くのエンジニアから頼られ、その知見や成果物が広く参照されている。
- 多くのエンジニアが現場で直面する課題を解決するOSSや開発ツールを提供し、社外の開発コミュニティへ広く貢献している。
- 自身の深い実践や検証に基づく技術記事・書籍の執筆や登壇を通じて、多くのエンジニアが実務で活用できる質の高い知見を発信している。
彼らが行うのは、自らの知識や経験、アイデアを、他者が活用できる形へと変えることだ。個別の課題から得た知見を汎化し、言葉や成果物として公開する。その過程や、公開後に寄せられるフィードバックからも学ぶ。実践と発信を繰り返しながら、知見を磨き続ける。
その問題設定や考え方、成果物が広く認知されるにつれ、技術コミュニティに新たな議論や実践が生まれる。それらは、さらに新たな手法や成果物へとつながっていく。こうして、技術コミュニティにおける知識や実践の発展を牽引する存在となる。
エンジニアがもたらすインパクト = スコープ × コンピテンシー
前節では、エンジニアが組織やコミュニティにもたらす価値、すなわち「インパクト」の具体像を、6つの立場から見てきた。
そのインパクトは、担う「スコープ」と、発揮する「コンピテンシー」の組み合わせに大きく左右される*2。そこで本節では、6タイプのエンジニアが、どのようなスコープを担い、どのようなコンピテンシーを発揮するのかを考察する。
スコープとは、その人が担う職務と責任の範囲である。ジョブディスクリプションに記される内容と言ってもよい。担う役割や役職によって、一定の範囲が定められやすい。ただし、日本ではスコープが明示されないことも多い。自ら役割を広げる人もいれば、狭く捉える人もいる。
コンピテンシーは、「ハイパフォーマーに共通して見られる行動特性」といった言われ方をする。少々わかりにくい。知識やスキル、経験といったその人の有する能力は、使わなければ宝の持ち腐れだ。それらを駆使し、成果に結びつける再現性のある思考や行動のパターン。これこそが、コンピテンシーである。
それでは、6タイプのエンジニアが持つスコープとコンピテンシーを考察してみよう。比較には、書籍『ITエンジニアの転職学』内のフレームワークを用いることにした。
6タイプのエンジニアが担うスコープを2軸で捉える
ここでは、6タイプのエンジニアが担うスコープを、2つの軸にプロットする。
縦軸は「どのような課題を解くか」を表す。上側はユーザー・事業・組織課題、下側は技術課題である。横軸は「どのように成果を生み出すか」を表す*3。左側は自らの専門性や成果物による貢献、右側は他者や組織を動かすことによる貢献である。

こうして眺めてみると、主に社外へ影響を与える⑥(社外の~)以外は、全体的に中央から右側に分布していることが分かる。他者から頼られ、「優れている」と評されるエンジニアは、自分一人の直接的な貢献に閉じず、リーダーシップを発揮し、他者や組織を通じてインパクトを広げているということだ。
上下方向については、どちらにも活躍の場がある。ユーザー・事業・組織課題を解くことも、技術課題を解くことも、優れたエンジニアとして評価される。
ただし、右上に配置された⑤(経営者に~)は、CTOやエンジニアリングVPに求められる役割とも大きく重なる。これらの役職は一般的に、エンジニアリングマネジメントのキャリアパス上に位置づけられる*4*5。つまり、優れたエンジニアであると同時に、エンジニアリングマネジメント職でも高く評価される人物像である。
そして、特にCTOは、スタッフプラスエンジニアとしてのICキャリアからも到達し得る。どちらの経路をたどったかによって、組織寄りか技術寄りか、そのリーダーシップの重心も変わるのだろう。
⑥(社外の~)のスコープは、その人の専門性による。図では技術課題を専門とする場合をイメージして下側をスコープとした。組織課題を専門とするなら、もちろん上側にスコープを持つことになる。
出典: James Stanier (著), 風間 勇志 (翻訳), 高口 太朗 (翻訳) 『シニアエンジニアリングリーダーのしごと ―組織を導き、育てる力を磨く』オライリー・ジャパン, 2026年5月20日, 「1.1.1 並行するキャリアパス」内の表を参考に筆者が作成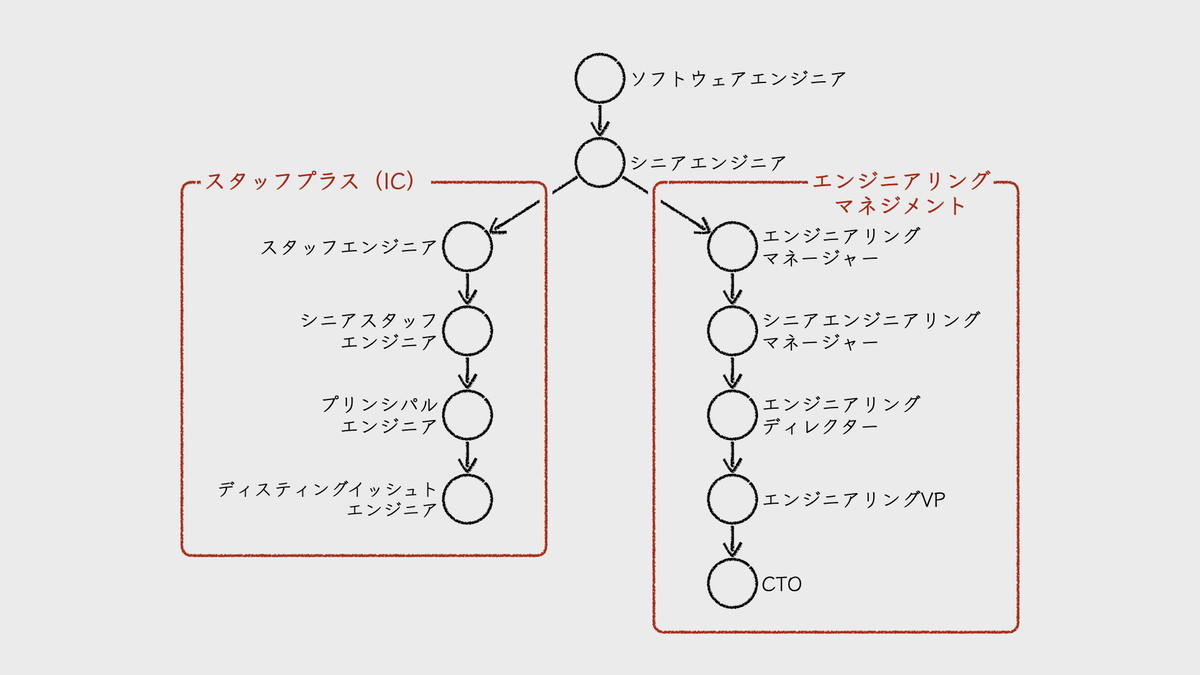
6タイプのエンジニアが発揮するコンピテンシーを6つの軸から捉える
次に、エンジニアの行動を6つの能力軸*6から捉え、6タイプごとにどの能力が強く表れているかを整理する。能力の組み合わせや発揮のされ方を眺めることで、それぞれのコンピテンシーが見えてくるはずだ。
表中の「◎」は特に強く、「○」は比較的強く、その能力の発揮が観察・評価されることを示す。一方、「—」は、その能力が発揮されないことを意味しない。そのタイプでは表立って観察されにくく、評価の中心にもなりにくい能力である。

6タイプのエンジニアすべてに共通するのは、「2. 専門性の深さと広さ」であるが、その表れ方はタイプによって異なる。専門性は、「◎」や「○」が付いた他の能力を発揮する土台として機能するからだ。
そうして専門性によって支えられる能力の重心が、①から⑤までで少しずつ異なる。その違いが、表にもよく表れている。
エンジニアリング現場に近い①(チーム内の~)や②(他チームの~)では、「1. 設計力・実装力」が強く表れる。ただし、①で評価される行動はテックリード*7に、②で評価される行動はアーキテクト*8に期待されるものと近い。前者は主にチームを対象に、技術的な方向を定め、実行を導く。後者は、複数のチームやシステムにまたがる重要な技術領域を対象に、その方向性や品質に責任を持つ。ただし、アーキテクトであれば、②の「1. 設計力・実装力」は、「○」より「◎」であって欲しいところか。
③(EMに~)は、①(チーム内の~)と②(他チームの~)の特徴を併せ持つ。だがこれは、パートナーとするEMが担うスコープにも左右される。単一のチームを担うEMであれば①に近く、複数のチームを統括するエンジニアリングディレクターであれば②にも近づく。今回の整理は、比較的後者に寄っている。
④(他職種の~)と⑤(経営者に~)を見てみると、やはり「5. 事業・顧客貢献」が特に強く出ている。両者の大きな違いは、「4. 組織貢献」に対する評価だ。
④で「4. 組織貢献」が「—」となるのは、ここでの組織貢献を、開発組織の能力や仕組みを高める行動として捉えているためだ。④では、そうした行動よりも、技術を事業や顧客の価値へつなぐ行動が直接評価される。
⑤で評価される能力は、CTOやエンジニアリングVPに求められる能力と大きく重なる。ICのキャリアパスでは、経営幹部のスコープを補完するスタッフプラスの「右腕」アーキタイプに近い。
⑥(社外の~)では、「6. 情報発信・プレゼンス」が際立つ。専門性を言葉や成果物へ変換し、組織の外へ届けることでインパクトを生み出すからだ。「1. 設計力・実装力」の評価は、扱う領域によって変わり得る。それでも、その活動の鍵を握るのが「2. 専門性の深さと広さ」であることに変わりはない。
EMに頼られるエンジニアと、EMには共通点がある
ここで少し趣向を変えて、EMのスコープとコンピテンシーも見てみよう。
分析に使用したフレームワークの出典元である書籍『ITエンジニアの転職学』には、年収1,000万円以上のEMを分析した結果が掲載されている*9。もちろん、高収入だからといって、優れたEMであるとは限らない。ここでは、このデータを比較のための参考材料として用いる。
このデータを参考に、スコープとコンピテンシーを書き出すと、下図のようになる。
出典: 赤川 朗 著『ITエンジニアの転職学 2万人の選択から見えた、後悔しないキャリア戦略』講談社, 2025年, 図2-1と図2-6を参考に筆者が作成
スコープを見ると、EMと③(EMに~)や⑤(経営者に~)には重なる領域が多い。両者は異なる役割を担いながらも、チームや組織を前進させるミッションを共有し、互いを補完するパートナーだからだ。
コンピテンシーにも共通点が多い。特に、「3. 推進力・プロジェクト貢献」と「4. 組織貢献」が強く表れる点は共通している。
特に③との近さからは、EMから評価されるエンジニアと、高収入層のEMとの間に、能力面での親和性が見えてくる。前者がエンジニアリングマネジメント職へ移る際には、それまで培った能力を活かしやすい。後者もICへ戻れば、③タイプのエンジニアとして能力を発揮しやすいのかもしれない。
もっとも、EMがICへ戻る動機は、③タイプとして活躍したいからではないだろう。どちらかと言えば、①(チーム内の~)や②(他チームの~)を念頭に置いたキャリアチェンジが多いように思える。EMと③の間に能力面での親和性があっても、本人が望む役割は別である。
AI時代のエンジニアは何が変わり、何が変わらないのか
AI時代を迎えた今、活躍するエンジニアのコンピテンシーには、どのような変化が起きるのだろうか。6つの能力軸ごとに整理してみよう。
- 設計力・実装力: 重心が変わる。
- 単純な量の側面で言えば、設計や実装は、AIによってコモディティ化し、相対的な価値が下がる。
- よりエンジニアに求められるのは、“優れたUX”や、“その実現を支え、継続的かつ安全に進化させるための構造”を見極める力ではないか。
- さらに、AIによる生成物の妥当性を判断し、一貫したシステムへ統合する力が求められる。
- 専門性の深さと広さ: 重心が変わる。
- AIは、膨大な情報量・知識量を有している。しかし、AI自身がそれを適切に使いこなせるわけではない。
- AIが現実世界の事情や制約のすべてにアクセスできるわけでもない。そこには、言語化されていない暗黙知も含まれる。
- だからこそ、エンジニアには、膨大な選択肢から最適なアプローチを導き出す専門性の深さと広さが問われる。
- 推進力・プロジェクト貢献: 重要性が増す。
- プロジェクトは、初期に大きな不確実性を抱え、実行と学習を通じてそれを減らしていく営みである。
- その過程には、トレードオフを伴う意思決定や、関係者間の調整と合意形成が数多く含まれる。AIによる加速で、こうした頻度も高まる。
- こうした意思決定を恐れず大胆に舵を切るリーダーシップが求められる。
- 組織貢献: 重要性が増す。
- 従来通り、チームや組織全体の成果を底上げし、組織の成長に寄与する力が求められるが、その足場がAIの登場で変化し続けている。
- 個々人がそれに追随するだけでは、タスク単位での個人間の処理速度の差が広がるだけである。それでは組織としての成果につながらない。
- 評価されるのは、自分だけがAIを巧みに使う人ではない。チーム全体や組織全体が安全かつ効果的に使える仕組みを作り、変化する環境に適応させられる人である。
- 事業・顧客貢献: 重要性が増す。
- AIによって加速したプロダクト開発では、職種ごとの分業はハンドオフによる時間的・文脈的ロスが大きくなる。
- したがって、チームは互いの専門性を越えて協働する真のクロスファンクショナル性が求められる。
- エンジニアは事業や顧客を深く知り、「なぜ、何を作るか」に積極的に関わり、デリバリー結果の価値を高めることに注力する。
- 情報発信・プレゼンス: 重要性は変わらない。
- 重要性は変わらないが、この能力を発揮するためのスキルや専門性は、より高度になる。
- AIによって、「アウトプットの民主化」のような状況が起きているからだ。
- このコモディティ化から抜け出してプレゼンスを示すには、AIを使っただけでは真似できない、自身のリアルな実践に根ざした独自性が不可欠になる。
以上のように、各能力の使われ方や重心、要求水準には変化が表れはじめている。これは、私自身の実感でもある。
しかし、今回整理したエンジニアの6タイプと、それぞれに見られるコンピテンシーの基本的なパターンは、おそらく変わらないだろう。
すべての能力を等しく高めることは困難だからこそ、自分はどのスコープで活躍するのか焦点を定めたい。そのスコープにおける関係性の中で、どの能力を伸ばすべきかを考えることも、AI時代のキャリアを描く一つの方法となるだろう。
◇ ◇ ◇ ◇ ◇
最後に、少しだけ拙著を紹介したい。
『チームの力で組織を動かす』では、ソフトウェア開発を加速するためのチーム設計・組織設計について体系的に解説している。この記事が「優れたエンジニアとはどのような人物か」を個人の側から考えたものだとすれば、本書は、エンジニアが力を発揮できる組織をどうつくるかを考えたものでもある。興味を持っていただけたなら、ぜひ手に取ってみてほしい。
参考文献
*1:Will Larson (著), 増井 雄一郎 (解説), 長谷川 圭 (翻訳)『スタッフエンジニア マネジメントを超えるリーダーシップ』日経BP, 2023年5月3日, 第1章内「スタッフエンジニアの典型」より
*2:James Stanier (著), 風間 勇志 (翻訳), 高口 太朗 (翻訳) 『シニアエンジニアリングリーダーのしごと ―組織を導き、育てる力を磨く』オライリー・ジャパン, 2026年5月20日, 「1.3 コンピテンシー」より
*3:赤川 朗 (著)『ITエンジニアの転職学 2万人の選択から見えた、後悔しないキャリア戦略』講談社, 2025年10月24日, 第2章内「ITエンジニアの8つのキャリアパスと年収別能力イメージ」より
*4:James Stanier (著), 風間 勇志 (翻訳), 高口 太朗 (翻訳) 『シニアエンジニアリングリーダーのしごと ―組織を導き、育てる力を磨く』オライリー・ジャパン, 2026年5月20日, 「1.1.1 並行するキャリアパス」より
*5:Will Larson (著), 増井 雄一郎 (解説), 長谷川 圭 (翻訳)『スタッフエンジニア マネジメントを超えるリーダーシップ』日経BP, 2023年5月3日, 第1章内の図「エンジニアリングのキャリアラダーにおける2本の路線」より
*6:赤川 朗 (著)『ITエンジニアの転職学 2万人の選択から見えた、後悔しないキャリア戦略』講談社, 2025年10月24日, 第2章内「6つの能力定義」より
*7:Will Larson (著), 増井 雄一郎 (解説), 長谷川 圭 (翻訳)『スタッフエンジニア マネジメントを超えるリーダーシップ』日経BP, 2023年5月3日, 第1章内「スタッフエンジニアの典型」より
*8:Will Larson (著), 増井 雄一郎 (解説), 長谷川 圭 (翻訳)『スタッフエンジニア マネジメントを超えるリーダーシップ』日経BP, 2023年5月3日, 第1章内「スタッフエンジニアの典型」より
*9:赤川 朗 (著)『ITエンジニアの転職学 2万人の選択から見えた、後悔しないキャリア戦略』講談社, 2025年10月24日, 第2章内「ITエンジニアの8つのキャリアパスと年収別能力イメージ」より