本記事は、Engineering Manager Advent Calendar 2020の21日目です。テーマとしては、プロジェクトマネジメント、プロダクトマネジメント領域を取り上げています。
--
ソフトウェアプロダクトの開発、特に、競争の激しいマーケットに置かれたプロダクトの開発は、次から次へと繰り返されるアップデートの間隔が短いほど良いとされる。背景として期待されているのは、そのスピードがユーザー価値やビジネス価値に与えるポジティブな効果だろう。それは主にふたつあると考えている。
ひとつめの効果は、価値を早期に生み出せるということ。
プロダクトのアップデートが価値に変わるのは、それがリリースされてからだ。言い換えれば、リリース時期が遅くなれば遅くなるほど、ユーザーにとってもビジネスにとっても、得られるはずであった価値の総量が目減りすることになる。遅延と引き換えにコストを支払ったと言ってもよい。
では、早くリリースすれば期待通りの価値の獲得が約束されているかと言うと、しかし現実はそんなに甘くない。開発チームが自信を持って送り出したアップデートが、ユーザーから不評を買うなんてことは、よく見られる光景だ。
そこで、もう一つの効果への期待が生まれる。それは、価値向上の学びとなるフィードバックを早期に得られること。
アップデートに対する評価は、ユーザーの反応を見なければわからない。最終的かつ最も確かなフィードバックを得る方法は、アップデートをリリースし、その真価をユーザーに問うことだ。そうすれば、そこから得た学びをプロダクトに還元できる。だから、リリースサイクルが短ければ短いほど、フィードバックループを高速に回せ、適応性を高めることにつながる。
このように、リリースを早める努力はその見返りとして、アップデートという単なるアウトプットを、価値という大きなアウトカムに変換してくれる。それだけに、この努力が開発チームの普遍的な重要成功要因であることは間違いないだろう。
本記事では、PBI(Product Backlog Item)のライフサイクルを中心に据え、「リリースを早めて価値を最大化するにはどうすれば良いのか?」という問いを、「遅延によって失われる価値(コスト)を小さくする」という観点から捉え直した上で考察を進める。つまり、先述のひとつめの効果を得ることをテーマとして扱う。もう一方の「学習サイクルを高速化して得られる価値を大きくする」という観点は、以前の記事でテーマとして扱った。興味があれば、そちらもご一読いただきたい。
以降ではまず、遅延そのものや、遅延によってコストが生み出されるメカニズムを明らかにする。そこでの結果に基づいて、PBIの優先順位付けアルゴリズムの改良と、リードタイムのチューニングをもって、遅延コストの積み上げを最小化する開発プロセスを考えていく。
遅延コストを生み出すメカニズム
完了の遅延と予定された遅延
あたり前の話だが、開発チームにとってリリースの遅延と言えば、リリースを予定していた日と実際にリリースが完了した日との差を指す言葉だ。12月15日にリリース予定だったものを、実際には12月22日にリリースすれば、7日間の遅延となる。この遅延による経済的影響は、「機会損失(opportunity lost)」と呼ばれたりする。

この7日間はしかしながら、開発チームから見た遅延だ。ビジネス視点の遅延としては、考慮が漏れている。それは、「機会費用(opportunity cost)」として影響するもう一つの遅延のことだ。機会費用とは、最大の利益を得るために意思決定されたトレードオフによって取り損ねる利益を言う。
開発チームにとっての最大のマイルストンであるリリース予定日は、常にトレードオフの中で決められている。同時に抱える複数のPBIを全て最優先にすることはできない。何らかの優先順位付けアルゴリズムに従い、いくつかのアップデート単位にまとめられてリリース日がプランニングされる。結果、最優先のPBI以外のリリース予定日は、それぞれが最短のリリース日に比べて数日から数週間、あるいは数ヶ月レベルで先延ばしになる。この先延ばしになった日数が、もう一つの遅延だ。この遅延によって取り損ねることになる利益が、機会費用となる。
これら二つの遅延を本記事では「完了遅延」「予定遅延」として区別する。先ほどの例で、最短のリリース日を12月1日だとすると、予定遅延は14日間となる。ビジネス視点では、完了遅延によって7日間の機会損失を支払うことになったという事実だけでなく、予定遅延によって既に14日間の機会費用を支払っているという感覚を持つことになるだろう。

ふたつの遅延に紛れ込む無自覚な遅延
プロダクトバックログから取り出されて開発を開始したワークアイテムが、一度の停滞もなく進捗を続け、リリースに至ることはまずないだろう。ほとんどのワークアイテムは、リソースが割り当たって進捗している「進行状態(work state)」と、リソースが割り当たらずに停滞している「待機状態(wait state)」を交互に繰り返しながらリリースに辿り着く。

もちろん、ワークアイテムが待機状態にあるからといって、開発チームが仕事を怠けているわけではない。むしろ忙しく働いた結果が、この待機状態を生み出していると言っても良い。チームが並行して進めている別のワークアイテムに人的リソースが奪われ、リソースが割り当たらなかった残りのワークアイテムが一時的に待機状態になっているのだ。
一般的に、プロダクトのアップデートには、複数のPBIの成果物が含まれている。単一のPBIのみでアップデートを行うケースは少ない。その理由はいくつか考えられるが、最も大きな理由は、予定遅延を最小限にとどめたいという要求だろう。
ビジネスの責任者にとって、利益を取り損ねることに繋がる予定遅延の選択は、少しでも避けたい。できる限り多くのPBIを、少しでも早いアップデートに含めてリリースしたいのだ。そのトレードオフが、機会費用の最小化、つまりは利益の最大化になると信じている。
しかしながら、この意思決定は逆効果になり得る。多くのPBIが含まれるようなバッチサイズの大きなアップデートほど、過剰なマルチタスクを引き起こし、待機状態を生み出す。頻発する待機状態が個々のワークアイテムのリードタイムを引き延ばし、結局はアップデートのリリース日を遅延させるからだ。
この遅延は、予定遅延のみ、あるいは予定遅延と完了遅延の両方に紛れ込む。
予定遅延を避けるために、一度のアップデートに多くのPBIを詰め込むほど、アップデートのリードタイムは長くなる。少なくとも、全てのPBIの合計ストーリーポイント以上には引き延ばされる。結局は予定遅延となる。
それだけではない。エンジニアなら経験的に知っている通り、PBIを多く含むような、バッチサイズの大きなアップデートは、完了遅延が起きやすい。
一方で、開発チームがその完了遅延を予測して避けようとする行為は、リードタイムに含まれる見積もりバッファを大きくし、リリース予定日を先延ばしにする。この遅延は、完了遅延としてカウントされるかわりに、予定遅延としてカウントされるようになる。遅延することには変わりがないが、この判断は、ユーザーやビジネスに対する「リリース予定日という約束の不履行」を避けられるだけマシだろう。
なお、バッチサイズが大きくなる理由は、これも含めいくつか考えられる。
- できる限り多くのPBIを、一つでも早いアップデートに含めてリリースしたい
- マーケットに対するリリースインパクトを大きくしたい
- 開発チームの人的リソースに空きを作りたくない
- リリース実施によるコストやリスクが大きいため、リリース回数を減らしたい
いずれにしても、一度のアップデートに複数のPBIを詰め込むと、マルチタスクとなりリードタイムを引き延ばす。この遅延を認識した上で、適切なトレードオフを行うべきだろう。
遅延の長さを決定付ける二種類の待機時間
遅延の長さは、二種類の待機時間によって決まる。一つは、PBIの追加日から開始日までの待機時間。もう一つは、開始からリリースまでの間に断続的に入り込む待機時間だ。

一度のアップデートに含めるPBIを絞れば絞るほど、開始までの待機時間が長いPBIが増える。逆に、アップデートに含めるPBIを増やすほど、開発後の待機時間が長くなってしまう。
これらのことから、どのPBIから開始すべきなのかの優先順位付けアルゴリズムの最適化と、リードタイムの短縮が、積み上がっていく遅延コストを小さくすることにつながりそうだ。以降は、それぞれの実現手段について考えていく。
優先順位付けアルゴリズムの改良
CoDを用いた遅延影響の定量化
何らかの意思決定を下す時はいつでも、状況を定量化して分析することが役に立つ。下記グラフは、遅延による影響を、遅延時間に比例して拡大するモデルとして表現している。
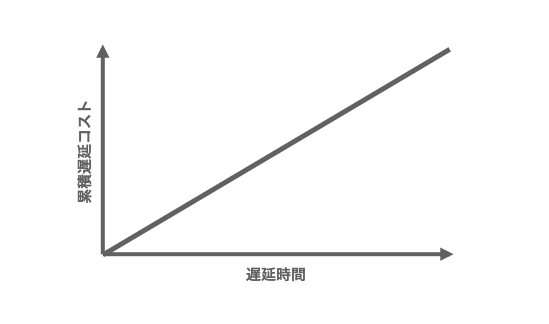
このグラフの傾きが大きいPBIほど、遅延の影響が大きい。Donald G Reinertsenは、この傾きをCoD(Cost of Delay)という名前で、遅延によって失われる価値の量をコストとして定量化することを提案した。このコストには、機会費用も機会損失も含まれている。
例えば、あるPBIのリリースによって、一年間で12,000千円の利益が生み出されると仮定する。この場合、リリースがひと月遅れるごとに1,000千円の利益を失うことになる。この1,000千円がCoDだ。
このように、Reinertsenの手法では、CoDに実際の金額を使用する。新規プロダクトをローンチするケースでは収支計画などから数字を引用できるが、既存プロダクトに対する変更を金額で見積もりるのは難しい。PBIひとつが、それだけで利益を上げるようなケースは多くない。サブスクリプションモデルのアプリに対するUI改善が、利益にどれだけの影響を与えるのか。技術的負債を返済することの価値は経済的にいくらになるのか。それらを金額に換算するのは困難だろう。
一方、SAFe (Scaled Agile Framework)は、CoDに金額を使わず、三つのコンポーネントに分けてフィボナッチ数で相対的に見積もることを推奨した。これだと、ストーリーポイントと同じ感覚で見積もることができ、開発チームへの導入障壁も下げられる。
UBV(User-Business Value)は、他のPBIとの相対的な価値の大きさを表す。価値が大きいほど、UBVは大きい。
TC(Time Criticality)は、遅延のインパクトを相対的に表す。リリース時期に対する制約が強いほど、TCは大きい。
RROE(Risk Reduction and/or Opportunity Enabling value)は、将来のデリバリーリスク軽減効果や、ビジネス機会創出の可能性を表す。その価値が高いほど、RROEは大きい。技術的負債の返済効果などは、ここに含めるのが良いだろう。
SAFeのこの方式は、価値を評価するUBV, RROEと、緊急性を評価するTCを足し合わすだけであり、非常にシンプルだ。しかし、その点を問題視する議論もある。価値を表すUBV, RROEが共に0であるなら、CoDは0であるべきという考え方だ。SAFeの方式では、緊急性を表すTCの値でCoDが決定されてしまう。
この問題を指摘しているJoshua Arnoldは、価値と緊急性を掛け合わせる方法を提案している。
以上は、時間軸に対してCoDが一定であることを想定した標準的なタイプ(standard cost of delay)を扱った。様々なケースを想定すると、時間軸に対してCoDが一定ではないタイプも考えられる。固定の日付に強く紐づいたPBIのCoD(fixed date cost of delay)や、緊急性が高いPBIのCoD(cost of delay tied to urgency)などだ。
PBIの特性に合わせてCoDは様々なタイプが考えらえるが、実際に利用するのは、standard cost of delayで十分だろう。CoDの使い分けは、労力に対して得られるメリットが小さいように思う。
WSJF戦略というアルゴリズムの選択
プロダクトバックログをキューとして捉えてみて欲しい。そこに詰め込まれたアイテムのデキューアルゴリズムは、FIFO(First In, First Out)になっていないだろうか。
機会費用を最小化することに焦点を当てると、PBIの優先順位付け戦略もそれを基準に評価することになる。ここで使えるのがWSJF(Weighted Shortest Job First)と呼ばれる優先順位付けモデルだ。WSJFは、重要度を期間で割った結果に基づいて優先順位を決める戦略だ。この重要度としてCoDを使ったものがCD3(Cost of Delay Division by Duration)と呼ばれている。
Durationは、対象とするPBIの開発に必要となる期間のことだ。推定リードタイムと言い換えても良い。代替として、PBIのストーリーポイントを利用する場合も多いだろう。
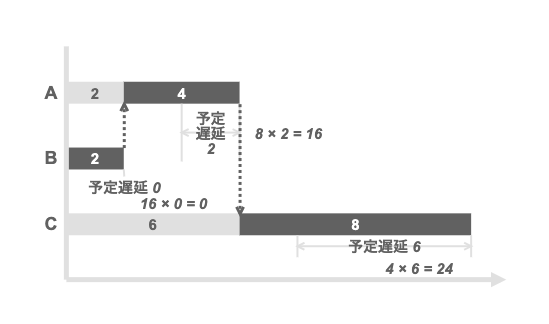
三つのPBIを例に、その優先順位を評価してみよう。
| PBI | CoD | Duration | WSJF |
|---|---|---|---|
| A | 8 | 4 | 2.0 |
| B | 16 | 2 | 8.0 |
| C | 4 | 8 | 0.5 |
WSJFの結果に従い、B→A→Cの順に開発・リリースした場合のCoDは、Aが16, Cが24となって、トータルの遅延コストが40となる。 Aは、BのDuration分だけ遅延するため、CoDの8に2を掛けて16となる。Cは、BとAのDurationを合わせた期間である6だけ遅延するため、CoDの4に6を掛けて24。それらを合わせて40という計算だ。
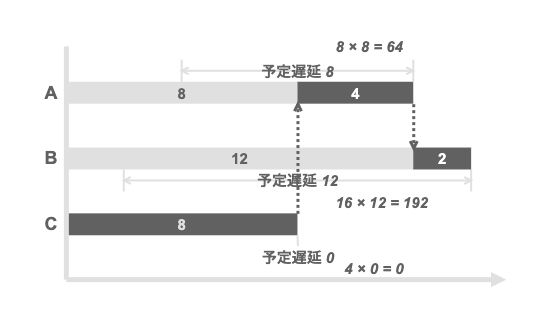
比較のために、逆順のC→ A→ Bとした場合は、Aが64, Bが192となり、トータルで256となる。WSJFで示された順序でリリースした方が、トータルの遅延コストが小さくなり、機会費用が相対的に小さく済むことがわかる。
WSJFの信頼性に関わるリードタイム推定精度問題
WSJFの良いところは、優先順位付けの根拠が誰にでもわかりやすい点にある。マネージャーや開発チームにとっても、ステークホルダーからリリース順序の根拠について問われた時に答えやすいだろう。
しかし、WSJFの利用にも課題はある。Duration, すなわちリードタイムの正確な推定が難しいのだ。推定リードタイムをストーリーポイントで代替しても良さそうだが、WSJFの信頼性を下げる可能性がある。同一のストーリーポイントとして推定されたPBIでも、実際のリードタイムにはばらつきがあるからだ。
同一のストーリーポイントと推定されたPBIの実績データを集め、グラフにプロットするとロングテールになる。横軸が実績リードタイムで、縦軸がそのリードタイムごとのPBIの数だ。ロングテール分布では、平均値は代表値として使えない。多くのデータがテール側にばらついてプロットされることになる。テールが横に長いほど、リードタイムの推定が困難であることを表している。
このばらつきの主な原因は、先にも述べた開発時の断続的な待機状態にあると考えられる。したがって、待機時間を削減できれば、テールが短くなり、リードタイムの推定に信頼が持てるようになるはずだ。その結果、WSJFによる優先順位付けの信頼性も上がるうえ、リードタイムも短くなる。これに取り組まない手はない。
リードタイムのチューニングと推定精度の向上
マルチタスクによる待機時間問題
マルチタスクと待機時間の関係について、もう少し深掘りしてみよう。
複雑な影響を無視して言えば、チームがひとつのワークアイテムに割り当てられる作業時間の割合 は、同時に抱えるワークアイテムの数
に反比例する。
なら、開発チームはそれだけに作業時間の全てを割り当てられ、
になる。
なら
,
なら
になる。
シングルタスクである場合の、あるワークアイテムのリードタイムを とすると、マルチタスクによる並列数が
なら、1日あたりの作業時間の割り当てが
になり、リードタイムは
で
になる。
なら、
となる。リードタイムの長さは、ワークアイテムの並列数に比例する。
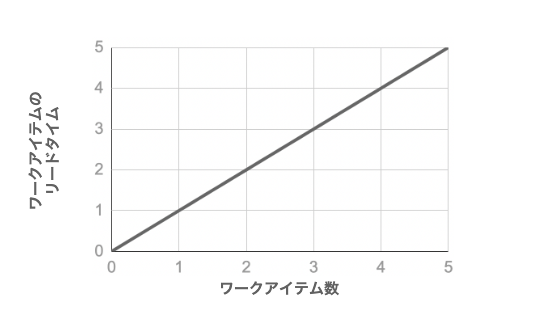
実際には、マルチタスクの作業の切り替えにスイッチングコストによるオーバーヘッドが発生するので、リードタイムはさらに延びることになる。スイッチ回数が多いほどそのコストは大きくなるが、その回数を推測できないから、影響の大きさを読むことができない。
さらに、マルチタスクの並列数は毎日一定ではない。だから、同じストーリーポイントのワークアイテムでも、そのリードタイムにばらつきがでる。
したがって、開発チームのマルチタスクを抑制することが、リードタイムを短縮することに有効な手段となり得る。
Flow Efficiencyを用いた進行効率の定量化
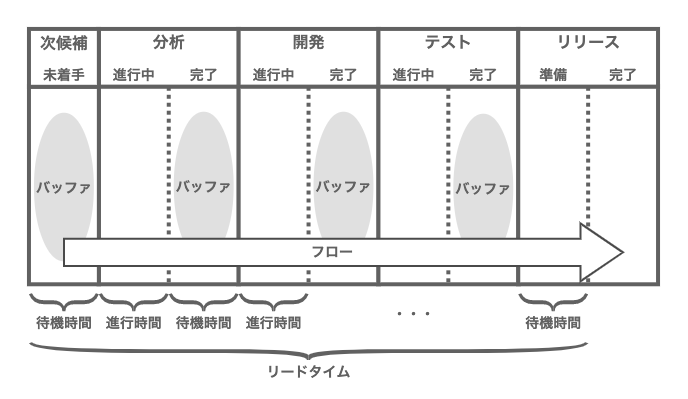
ワークアイテムの進行時間(work time)と待機時間(wait time)に焦点をあてるならば、まずはそれを可視化することが第一ステップとなる。そこでFlow Efficiencyというメトリクスを使う。Process Cycle Efficiencyや、Task Efficiencyとも呼ばれる。日本語では「フロー効率」と呼ばれているようだ。
一目瞭然であるが、Flow Efficiencyは、リードタイム(lead time)に占める進行時間(work time)の割合という形で、PBIの開発に要した期間の効率性を示す。このメトリクス値が大きいほど、待機状態による遅延が小さく、開発が効率よく進行したと言える。
チームのFlow Efficiencyを算出するには、ワークアイテムごとの進行時間の計測を始めなければならない。開発プロセスをいくつかのフェーズに分け、フェーズごとの開始日、終了日を記録する程度で良いだろう。少々粗いデータにはなるが、正確さを追い求め過ぎても、労力ばかりで大きな見返りは期待できない。チームがリーン開発のカンバンボードを導入しているのなら、ステージごとに開始日、終了日を記録していくイメージだ。
カンバンボードは、直線的な順序を持ついくつかのステージ(工程)で構成されている。このパイプラインを、カードと呼ばれるワークアイテムが流れていくことで、リリースにいたる。ひとつのステージを終えたカードは、次のステージでの作業が始まるまでの間、その手前のバッファに入る。カードがステージに入っている期間が進行時間、バッファにいる期間が待機時間となる。
もし、算出したスコアが8%程度でも、落胆する必要はない。Flow Efficiencyをどのように計測するかにもよるが、スコアは概ね、1%から25%の範囲に入るようだ。
いずれにしても、スコアを絶対値として他のチームと比較することにはあまり意味はない。ベロシティと同様に、チームの成熟度を知るための相対的な指標として利用できれば良い。
WIP制限でのマルチタスクの抑制とボトルネックの可視化
ワークアイテムごとのFlow Efficiencyを得たところで、次にやるべきことは、そのスコアの改善だ。その手段として、マルチタスクをコントロールする。メトリクスを悪化させる要因である無自覚な待機時間を抑制するということだ。
マルチタスクをコントロールするために、その状況を定量化・可視化し、並列数に閾値を設ける。先述のFlow Efficiencyの計測では、開発プロセスに含まれるフェーズをマネジメントする単位とした。ここでもフェーズごとに、仕掛かり中のワークアイテムの数を制限するのが良いだろう。
その最適な方法として、リーン開発ではお馴染みの 「WIP制限」というプラクティスを使う。WIPとは、Work In Progressの略で、仕掛かり中のカードを意味する。WIP制限では、カンバンボード上のステージごとに、チームが同時に取り組めるWIPの数を制限することで、過剰なマルチタスクを抑制する。
ステージ内のカード数が制限に達すると、そのステージでは新たなカードに取り組むことができなくなる。この状態を放置すると、ステージに入れないカードがバッファにどんどん積み上がっていく。これはボード上を流れるカードをせき止めるボトルネックだ。開発チームは、ボトルネックとなったステージのWIPを減らすことに注力することになるだろう。
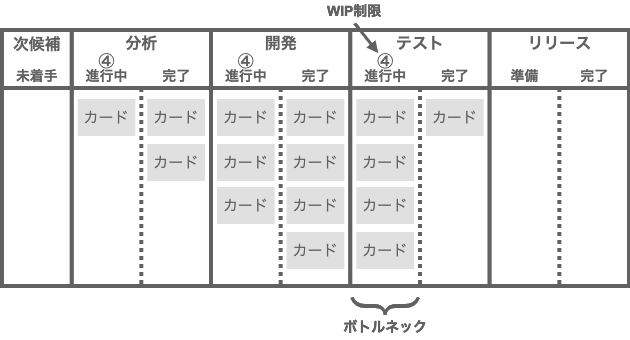
WIP制限の良いところは、マルチタスクを減らして待機時間を短くするだけでなく、フロー上のボトルネックを明らかにして、リードタイムを縮める方向に開発チームの行動を誘導する点にある。
逆にWIP制限を導入しないと、いくつものカードをステージに入れることだって出来てしまう。そうすると、バッファで待機しているはずのカードが不可視になる。見かけ上の待機時間がなくなるので、当然ながら、Flow Efficiencyのスコアが上がってしまう。これではメトリクスが意味をなさない。こういった問題からも、WIP制限はぜひ導入すべきプラクティスだと言えそうだ。
制限数をどの程度にすれば良いかは、運用しながら調節するしかない。大まかな基準としてはチームのメンバー数だろう。これより大きな数字は、確実にマルチタスクになるからだ。もしペアプロやモブプロを導入しているチームなら、この基準値はさらに小さい。
これで、Flow Efficiencyのスコアが向上し始める。また、待機時間が減ることでワークアイテムのリードタイムが安定する。この安定が、リードタイム分布のテールを短くし、結果としてリードタイムの推定精度が高まるだろう。これでようやく、WSJFの分母の信頼性が上がり、PBIの優先順位付け精度も向上する。
なお、Flow Efficiencyは、100%を目指すようなものでもない。カンバンコミュニティで報告された最高のケースでも40%程度のようだ。
最後に
エンジニアリングに携わっていると、システムや開発プロセスに限らず、何らかしらの主体やその機能を対象に、パフォーマンスを高めるミッションを担うことがある。
そういった時、対象に再現性がないなら、対象のポテンシャル自体を引き上げるより、対象が本来持っているはずのポテンシャルを引き出すことに注力した方が、早く大きな効果を得られることが多いと感じている。前者の取り組みは「スケール」、後者は「チューニング」という言葉がしっくりくる。
チューニングとは、ある目的に合わせ、対象が内包するプロセスやパラメータを最適化したり、阻害要因を取り除く行為だ。こうして、本来のポテンシャルを引き出し、目的に合わせたパフォーマンスを得る。本記事の内容もまさに、チューニングによって、PBIが本来持つ価値を最大限に引き出すことだった。その戦略が、遅延コストによって損なわれる価値を、全体最適の観点で最小限に抑えることだ。
この戦略の中心は、CoDとWSJFにある。これらを使い、PBIそれぞれのリリースをプランニングする。そして、そのプランにそってPBIの開発を開始し、最短距離でリリースする。この早期のリリースが、ユーザーからの早期のフィードバック獲得につながる。こうして学習したチームは、価値を生み出す確度の高いアイデアをPBIとして追加する。そしてまた、CoDとWSJFを使い、PBIのリリースをプランニングする。このサイクルを回し続ける。すべてはプロダクトのユーザー価値とビジネス価値を高めるために。