その重要性ゆえに、チームや組織はこれらのメトリクスの計測と可視化に努める。可能な範囲で正確な値が欲しい。そうして、チケット管理ツールやバージョン管理システムからテレメトリを収集、集計し、チームのモニタリングダッシュボードにその実績値を可視化するのだ。
しかし、しばらくメトリクスを運用してみると、その扱いづらさに気づく。計測値や集計値のばらつきが大きく、それをどう理解すれば良いのか、どう評価すれば良いのか悩むのだ。
本稿はこの問題について考える。結論としては、実測値を使うまでもなく、「チームの誰もが知っているデプロイ頻度とリードタイム」を用いれば十分、というものだ。2週間のイテレーションごとにデプロイしているなら、2週間に1回のデプロイ頻度であり、リードタイムは2週間とする。これには前提も付くが、実践向きだし手軽だ。詳細は後述する。
- 前提とするチーム
- メトリクスの定義
- ケース1. 緊急対応
- ケース2. 開発の保留
- ケース3. 長期の連休
- チームの誰もが知っているデプロイ頻度とリードタイム
- デプロイ頻度とリードタイムは「フロー」をモニタリングするメトリクス
- フローを速くする
- フローの数を増やす
- バッチ方式からオンデマンドへ
- 目指すはバリューストリーム全体のフローを改善すること
前提とするチーム
問題を掘り下げるにあたり、前提とする開発プロセスやチームの責務について、ここで明確にする。
ここでのチームは、スクラムをはじめとするイテレーティブなプロセスを持つソフトウェア開発手法を採用している。イテレーションは、1週間や2週間といった固定の期間で繰り返される。
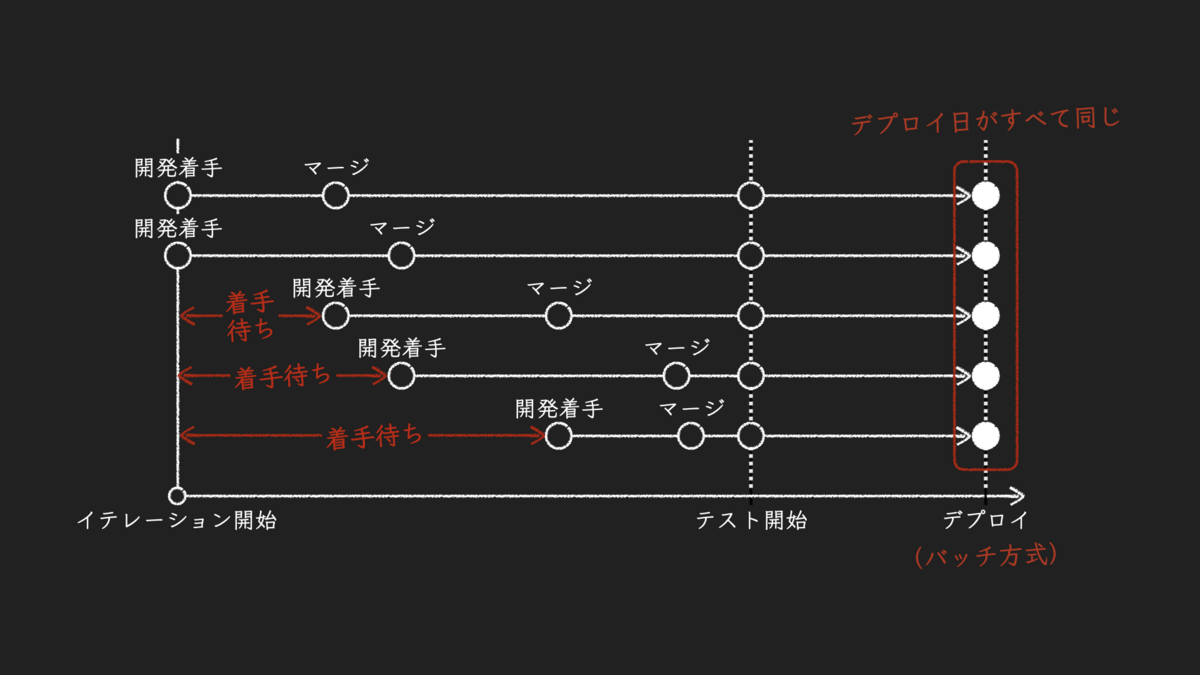
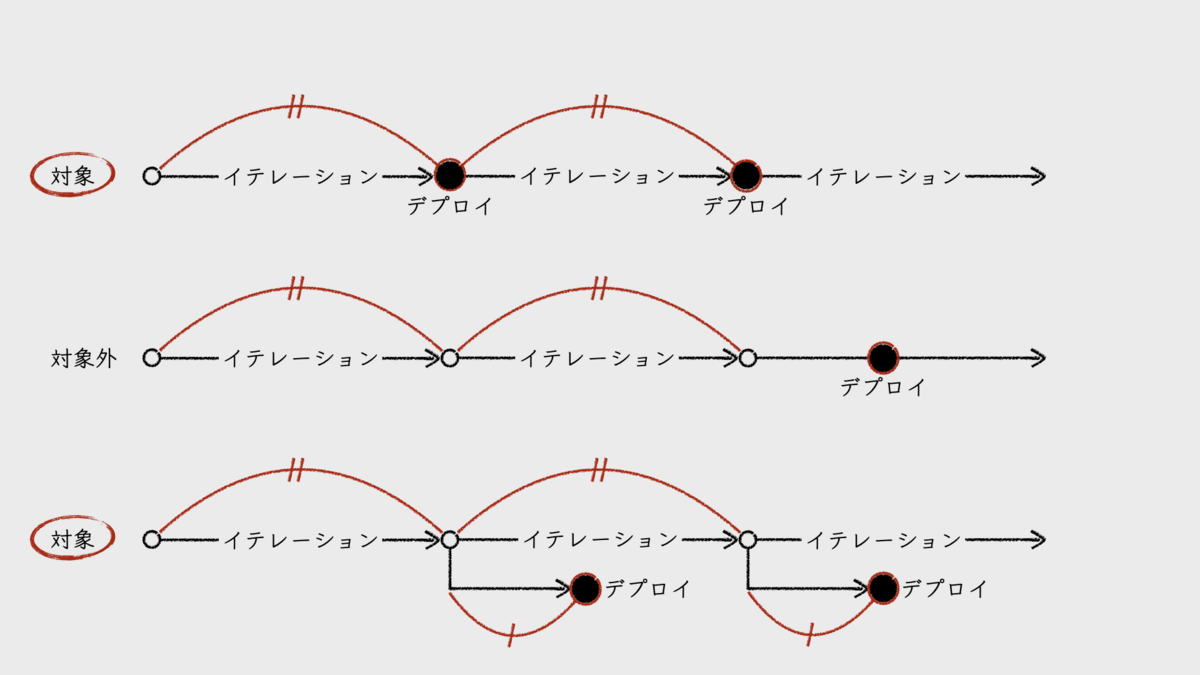
イテレーション終了直前のインクリメントは、本番環境へのデプロイが可能な状態となる。そして、前提とするチームでは、直近1回分のイテレーションによるインクリメントのみを対象としてデプロイする運用を採用している。複数のイテレーションを経てからデプロイするプロセスは対象外とする。
なお、イテレーション終了後から、いわゆるテストフェーズなどを経てデプロイするプロセスであっても構わない。
本番環境へのデプロイは、開発したチーム自身が責務を持つ。デプロイが手作業であるか、自動化されているかは問わない。
メトリクスの定義
次に、「デプロイ頻度」と「リードタイム」の定義について。
まずは「デプロイ頻度」であるが、これは、「どれぐらいの期間ごとに1回のデプロイを実施しているか」である。DORAメトリクスの2023年版調査アンケートでは、次のように問われている。これを見るとイメージしやすいだろう。
How often does your organization deploy code to production or release it to end users?
- Fewer than once per six months
- Between once per month and once every 6 months
- Between once per week and once per month
- Between once per day and once per week
- Between once per hour and once per day
- On demand (multiple deploys per day)
- I don't know or not applicable
「リードタイム」についてもDORAのアンケート設問を見てみよう。なお、DORAメトリクスが対象とするリードタイムは、「変更のリードタイム(lead time for changes)」だ。
What is your lead time for changes (i.e., how long does it take to go from code committed to code successfully running in production)?
- More than six months
- Between one month and six months
- Between one week and one month
- Between one day and one week
- Less than one day
- Less than one hour
- I don't know or not applicable
「変更のリードタイム」の定義は、設問にもあるように、「コードがコミットされてから、それが本番環境で正常に稼働するまでの時間」となっている。つまり、実装時間は含まれない。
継続的インテグレーション(CI)を重視するDevOpsの観点から考えて、これが意味する開始点は、変更したコードが統合ブランチに取り込まれた時点だろう。CIが整備されているチームであれば、変更内容がマージされてCIが動作し、それが正常終了したタイミングが、変更のリードタイムの開始点ではないだろうか。
便宜上、私は、開発項目ごとのフローとそのリードタイムを次の図のように2つに分けている。1つは、フローのうち、設計を含む開発に着手してから、その変更がレビューされ、統合ブランチに取り込まれるまで。2つめは、そこから本番環境にデプロイするまで。前者の範囲を「開発フェーズ」、後者の範囲を「製造フェーズ」と呼ぶことにする。DORAメトリクスの「変更のリードタイム」は、製造フェーズのリードタイムのことだ。
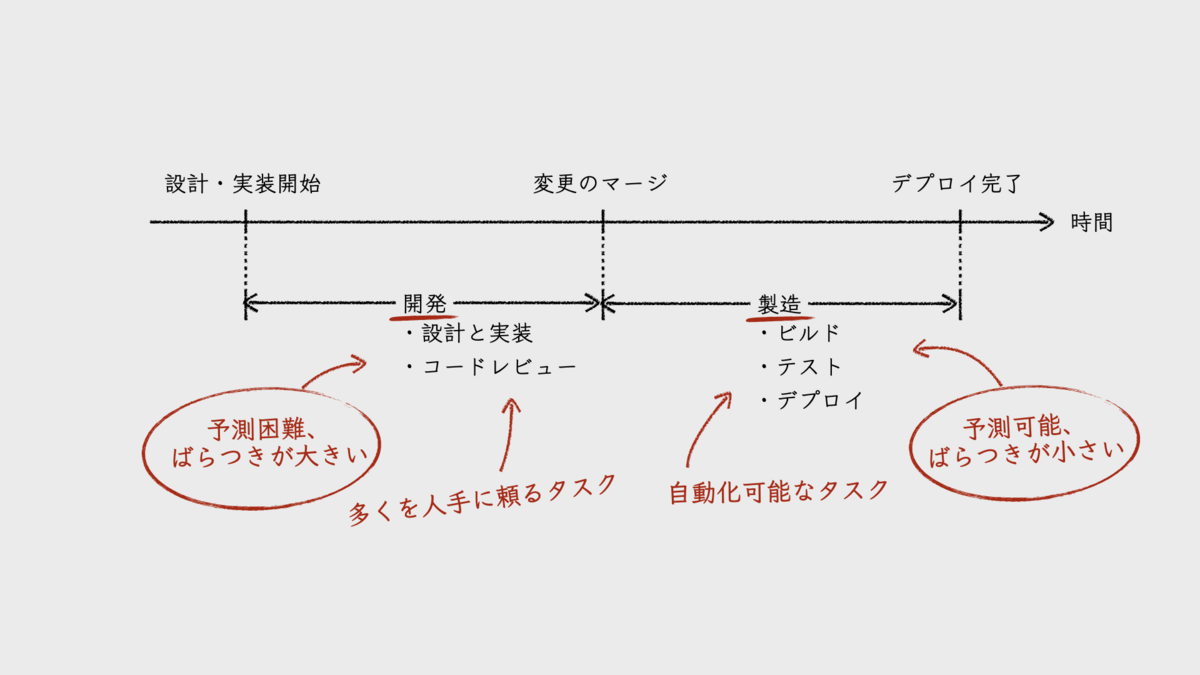
このように分ける理由は、両者のリードタイムの特性が大きく異なるからである。
開発フェーズのリードタイムについては、noteの記事『ブラックボックスになりがちな開発チームの内部状況を指標を用いて可視化する』の中で次のように書いた。
開発フェーズのリードタイムは、開発項目ごとの計測値に大きなばらつきがあることが特徴です。開発項目の開発規模や、担当者の稼働状況・スキルなどに大きな影響を受けるからです。これは、このフェーズのプロセスに含まれるタスク(設計・実装、コードレビュー)が現状では多くを人手に頼らざるを得ないからだとも言えるでしょう。見積りによる予測は行うものの、その通りになるとも限らず、予測困難で不確実な指標だとも言えます。また、計測値は正規分布とならないため、平均値を代表値として扱えないことにも注意が必要です。
製造フェーズについては、次のとおりだ。
製造フェーズのリードタイムは、開発フェーズとは違い、プロセスが洗練するほどばらつきが小さく、一定になる傾向があります。それは、このフェーズのプロセスに含まれるタスク(ビルド、テスト、デプロイなど)の多くが自動化可能だからです。テストは人手に頼るべき領域が多少は残るものの、全体的な自動化が進むほど予測可能で不確実性の低い指標となるのが特徴です。
以降で、デプロイ頻度とリードタイムの計測値の扱いづらさについて、いくつか例をあげてみる。
ケース1. 緊急対応
ソフトウェアシステムには本番トラブルによる緊急対応が付きものであるが、その影響が計測値にあらわれる。
緊急対応による本番環境へのデプロイが発生する回数が多いほど、デプロイ頻度が高くなる。しかし、デプロイ頻度は、その値が大きい方が「チームのパフォーマンスが優れている」とされるメトリクスだ。緊急対応によって高くなった集計値が、パフォーマンスが高い状態をあらわすわけがない。
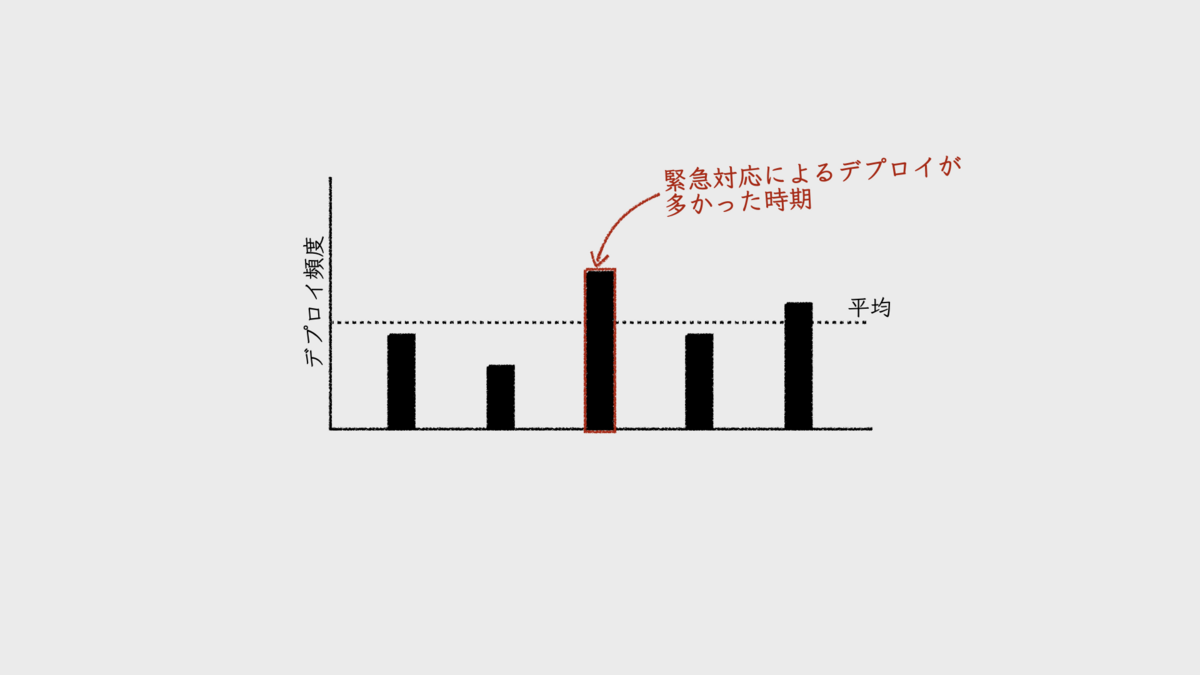
加えて、素早さが求められる緊急対応時のフローは、開発フェーズのリードタイムが短くなる。1時間未満、あるいは数時間程度で問題箇所の修正を終わらせることが多い。そして、製造フェーズの非自動化ステップのいくつかが簡略化されたりもする。そのため、フェーズ内に自動化されていないステップが多く含まれているチームほど、いつもより、製造フェーズのリードタイムも短くなるのだ。
結果として、任意期間におけるリードタイムの代表値(中央値など)が、これらの影響を受けて小さくなる。つまり、チームのパフォーマンスが、実態よりも優れているように見えてしまうのだ。
いずれも、緊急対応に関係する測定値を除去して集計することもできるが、それもわずらわしい。DORAメトリクスの1つである「変更失敗率(change failure rate)」と合わせて眺めることで、緊急対応による影響が読み取れなくもないが、どこまで影響したのかまでは明確にはならない。
ケース2. 開発の保留
仕掛中の開発項目が、何らかの理由でしばらく保留となることがある。そうすると、その変更内容を、フィーチャーブランチといった、統合ブランチ以外の場所に置いたままで、しばらく放置することになる。そして開発が再開したら、残った実装を進め、その変更内容を統合ブランチに取り込む。すると、開発フェーズがとんでもなく長いリードタイムが記録されることになる。

このような「はずれ値」は、リードタイムの代表値を大きくする要因となる。これをどうとらえれば良いだろうか。
保留となった理由には、チームから見て外的な要因と、内的な要因があり得る。
顧客からの要求変更に影響を受け、保留せざるを得ないような場合は外的要因だろう。その結果としてリードタイムが伸びたとしても、それを「チームのパフォーマンスが低い」と言うことはできない。当初の計画のまま開発を続けても、顧客にとっての価値にならないからだ。しかし、こういったことが頻発するなら、なにか問題があるとも考えられる。
内的要因としては、たとえば、メンバーの稼働率(リソース効率)を高めようとするケースが保留を頻発させることがある。チームの時間を隙間なく埋めるために、合い間に優先度の低い開発項目に着手するからだ。そしてその途中で、もともと計画していた開発項目に着手すべきタイミングがやってきて、仕掛中の仕事は保留となる。特に、時間単価で給与を支払うメンバーに対して、顕著にこうなってしまうようだ。これは問題だろう。
いずれにしても、これらの問題は、リードタイムの計測値から検知するようなものではない。逆に、これらの問題の解決状況を、リードタイムの計測値で判断するものでもない。したがって、保留問題がリードタイムに与える影響をどうとらえれば良いのか、悩むことになる。
ケース3. 長期の連休
年末年始やゴールデンウィークのような長い連休を挟むと、リードタイムが目立って長くなる。
連休前に仕掛中だった開発項目の作業を連休後に再開させると、あいだに挟まれた連休の日数分が、開発フェーズのリードタイムに含まれて記録されてしまう。また、連休前に開発フェーズが完了している開発項目であっても、長い連休の影響でイテレーション期間が長くなることで、製造フェーズのリードタイムも伸びる。
結果として、フロー全体のリードタイムが伸びた開発項目が記録されることになる。デプロイ頻度も下がることになるだろう。

メトリクスだけを見ると、チームのパフォーマンスが相対的に低くなったように見える。確かに、普段であれば、デプロイ日やリリース日を1週間ほど早くできただろう。しかしこの遅れは、単に連休の影響である。パフォーマンスとは関係がない。
この問題に対し、チーム内で「営業日だけカウントすべき」といった意見が出るかもしれない。計測値にそのような処理を加えるためには、休業日カレンダーを持たせることになる。本当にそこまで凝ったことをすべきか。また、それを言うなら次は「仕掛中の開発項目を持ったメンバーが休んだ日はどうする?」といった疑問もわいてくる。不毛だ。
そもそも、チーム内でこういった議論が起きるようなら、メトリクスが自己目的化してしまっていることを疑ってみるべきだろう。特に、メトリクスの悪化を避けることを目的に、デプロイ日を早めて連休前に済ませようとする意識が働くようになっていたら、決定的だ。
チームの誰もが知っているデプロイ頻度とリードタイム
このように、デプロイ頻度やリードタイムの計測値から、チームのパフォーマンスを読み取ることは思ったより簡単ではない。
それでは、チームのデプロイ頻度やリードタイムをどうやって知ればいいのか。その答えはシンプルだ。
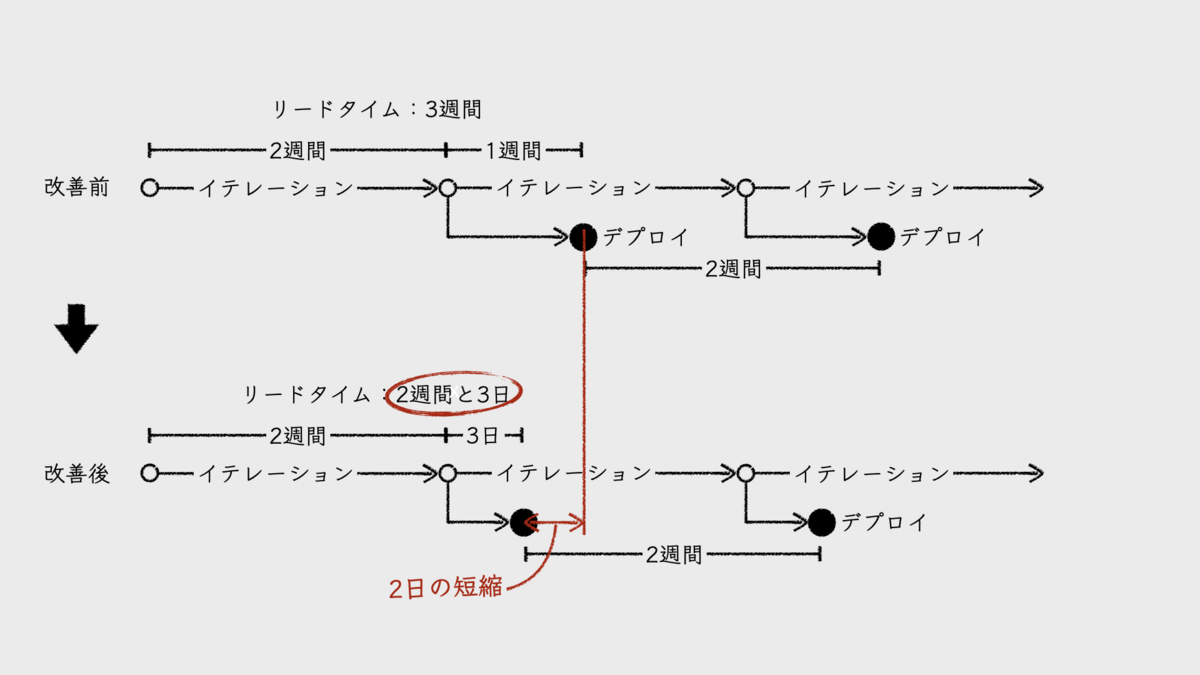
イテレーション期間が2週間であれば、デプロイ頻度を「2週間に1回」とする。リードタイムは、開発フェーズと製造フェーズをあわせて「2週間」だ。もし、2週間のイテレーションのあとに1週間のテストフェーズやセキュリティチェックなどを経てデプロイしているのなら、リードタイムは「3週間」とする。もちろん、先述のとおり、これらはイテレーションごとにデプロイしていることを前提とする。
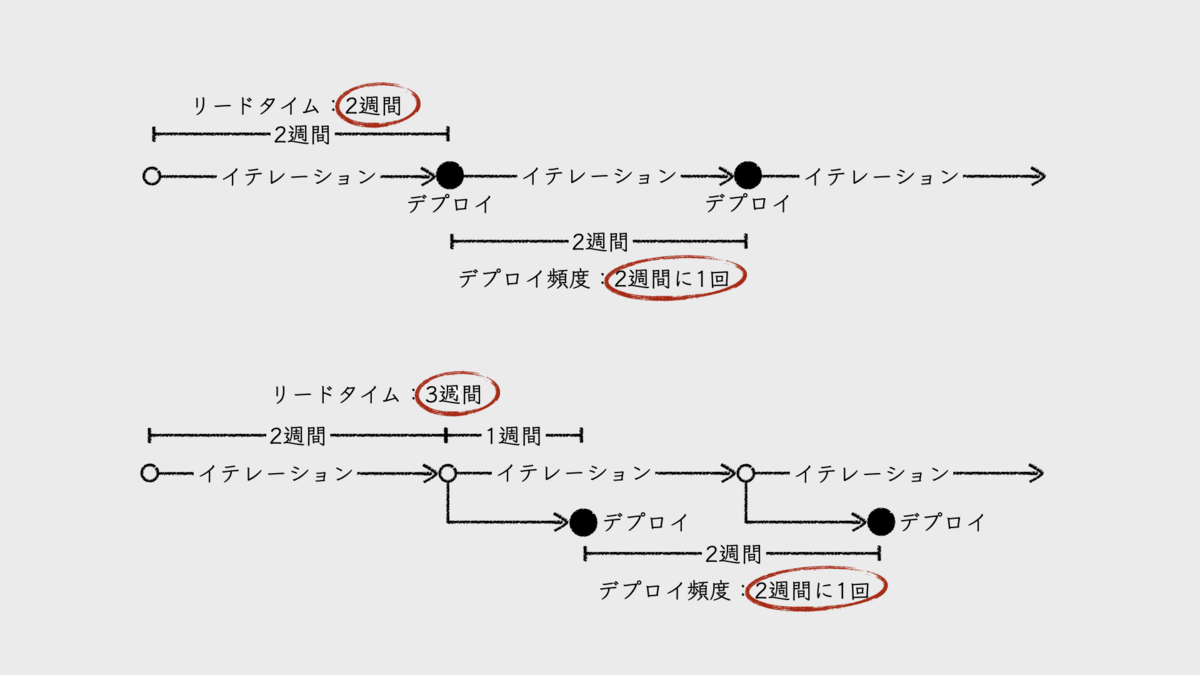
これが、「チームの誰もが知っているデプロイ頻度とリードタイム」である。計測値がない状態で、チームメンバーに「デプロイ頻度とリードタイムは?」と問えば、おそらく誰もがこのように答えるのではないだろうか。
そもそも、本稿が前提としている開発プロセスは、バッチ方式のデプロイだ。イテレーション内で対応する開発項目がすべて同時にデプロイされるということ。イテレーション内でいつ開発に着手したとしても、リードタイムの終端であるデプロイ日が同じになる。
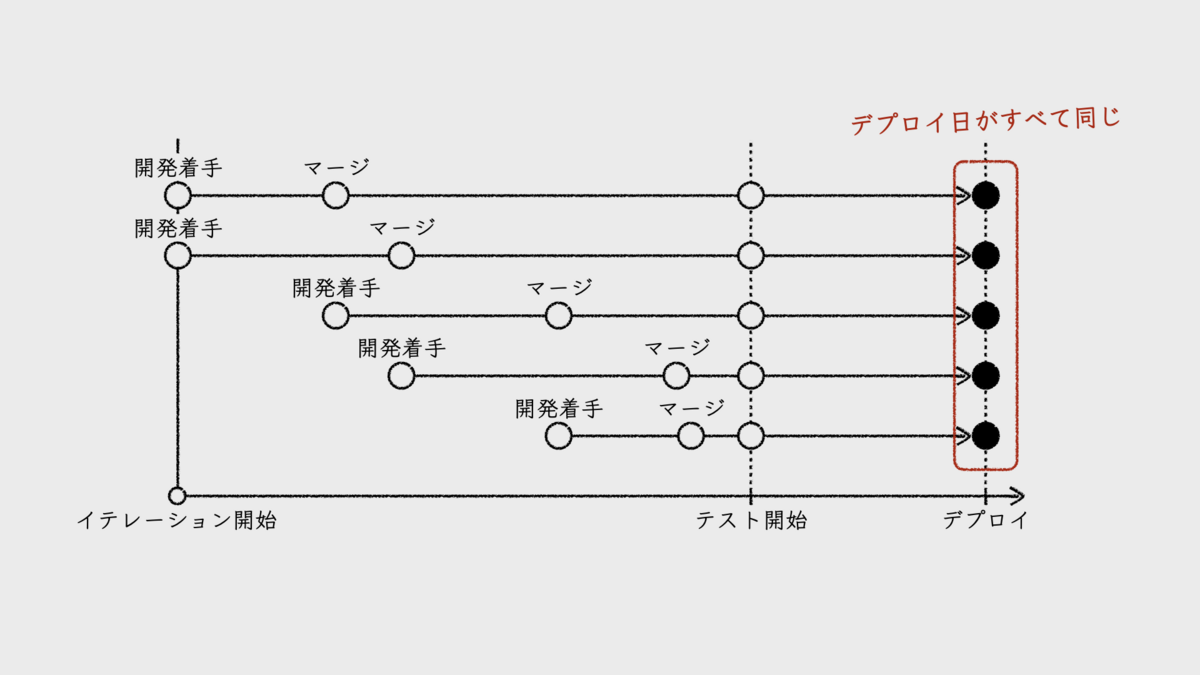
つまり、開発項目ごとのリードタイムの違いは、開発着手日の違いでしかない。開発着手日が遅いほど、リードタイムが短くなるということだ。この違いに着目することに、意味があるのだろうか。この待ち時間をリードタイムに加えれば、すべての開発項目のリードタイムが同じになるのだ。
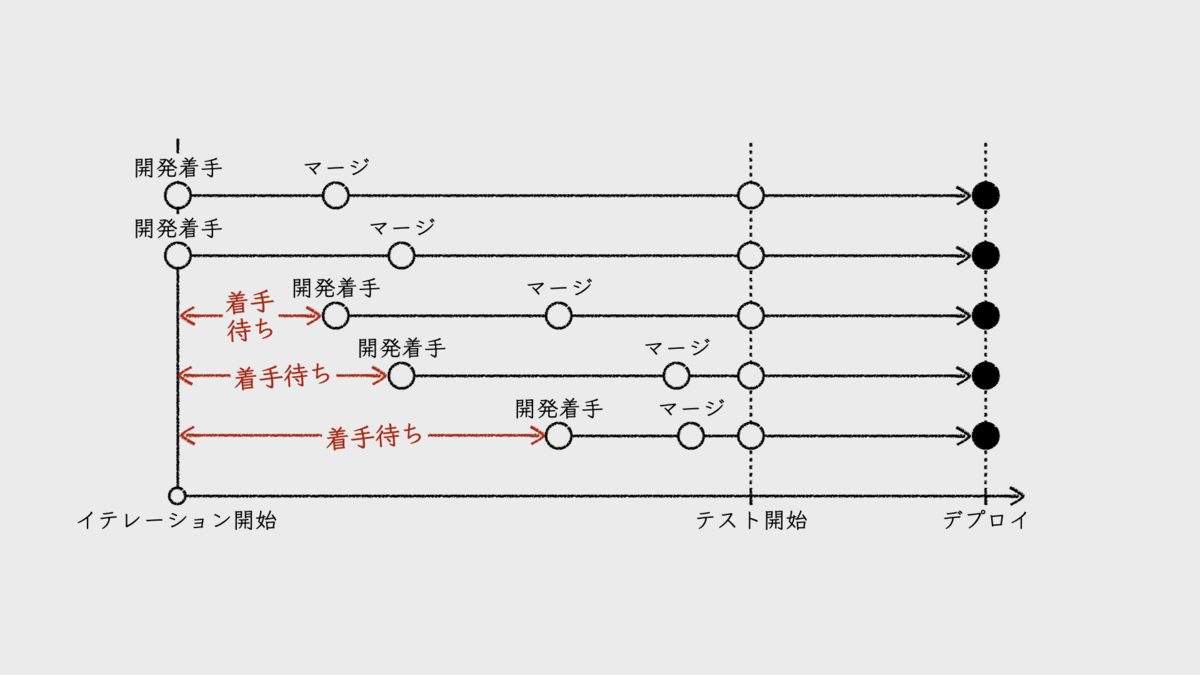
だから、チームが注目すべきリードタイムは、開発項目ごとに計測したリードタイムではなく、チームの誰もが知っているリードタイムで十分なのだ。デプロイ頻度についても、一定のサイクルでデプロイを実施しているのだから、計測するまでもない。
もちろん、先述した緊急対応といった例外ケースはその限りではないが、これは通常のフローとは別物だ。通常のフローと例外のフローを統合管理する必要はない。改善対象としてそれぞれ別で管理すべきだからだ。
また、通常のフローであっても、時にはイテレーション内で完了できない開発項目も出てくるだろう。しかし、そんなものはリードタイムを計測しなくてもチームは把握している。完了しないことが問題だとチームが考えるなら、原因を分析して改善を進めればいいだけの話だ。
デプロイ頻度とリードタイムは「フロー」をモニタリングするメトリクス
デプロイ頻度やリードタイムは、「フロー」をモニタリングするためのメトリクスだ。DORAメトリクスの設計者であるニコール・フォースグレン(Nicole Forsgren)らが開発した「SPACEフレームワーク」においても、デプロイ頻度と変更のリードタイムは、「Efficiency and flow」に位置づけられている。
実現したいことは、メトリクスの改善ではなく、フローの改善なのだ。「メトリクスを改善しよう」と意識しすぎると、この観点を見失いやすい。フローの改善によって、ソフトウェアデリバリのパフォーマンスを高める。そして、DORAの調査結果にもあるように、それが、収益性や市場占有率といった組織パフォーマンスを高めることに繋がる。それを期待しているのだ。
フロー改善のために考えられる戦略は2つ、「フローを速くする」ことと、「フローの数を増やす」ことだ。どのような施策を進めるにしても、このどちらが狙いの施策であるかを念頭に置いて、改善サイクルをまわすことが重要だろう。

フローを速くする
固定イテレーション単位でのバッチ方式デプロイを前提とするなら、イテレーション単位のフローに目を向けることになる。開発項目単位のフローをいくら速くしても、デプロイ日が早まることはないからだ。

イテレーション単位のフローを速くする方法の1つは、イテレーション期間を短くすることだ。簡単ではないし、限度もあるが、確実にフローが速くなる。結果として、デプロイ頻度が高くなり、リードタイムも短くなる。
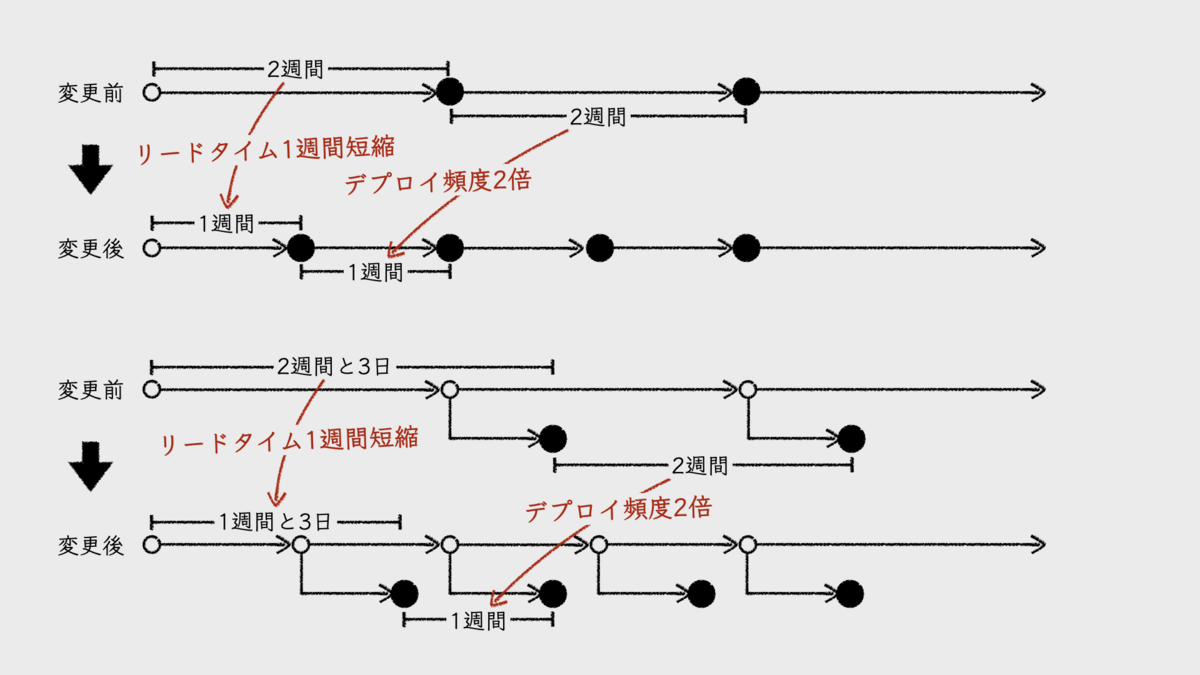
もし、イテレーション終了後にテストなどを経てデプロイしているのなら、デプロイメントパイプラインの整備も有効だ。パイプラインの自動化率を高め、さらにその効率を高めるのだ。そうすることで、イテレーション終了からデプロイまでの期間が削減される。結果として、リードタイムが短くなる。
フローの数を増やす
フローの数を増やすことについては、イテレーション単位のフローに目を向けてしまうと、それは単に「チームを増やす」ことになってしまう。それは本稿のテーマとは外れるので、ここは開発項目単位のフローについて考える。
固定イテレーション単位でのバッチ方式デプロイの場合、フローの数を増やすと、バッチサイズが大きくなる。「フローの数を増やす」とは、単位期間あたりに完了させられる開発項目の数を増やすということだ。つまり、1回のイテレーションで完了させる開発項目が増える。これによって、チームのベロシティは大きくなるが、デプロイ頻度もリードタイムも変化しない。
ここで重要なことは、フローの数が増えることで、イテレーション期間の短縮を進めやすくなるという点だろう。
イテレーション期間の短縮も良し悪しなのだ。2週間のイテレーションを1週間に縮めるのはハードルが高い。期間が短くなる分、1度のイテレーションで使える開発時間は小さくなる。それに、イテレーション初日のプランニングや、最終日のレビューや振り返り、あるいはプロダクトバックログのリファインメントなどで開発時間が圧迫されてしまうかもしれない。
バッチサイズが小さい方が良いとは言え、小さすぎるのも困る。フローの数を増やすことで、その点をカバーしやすくなる。
フローの数を増やすための方法の1つとしても、デプロイメントパイプラインの整備が有効だろう。イテレーション期間内にデプロイを実施しているチームであれば、これによってコード実装に使える期間が長くなるからだ。
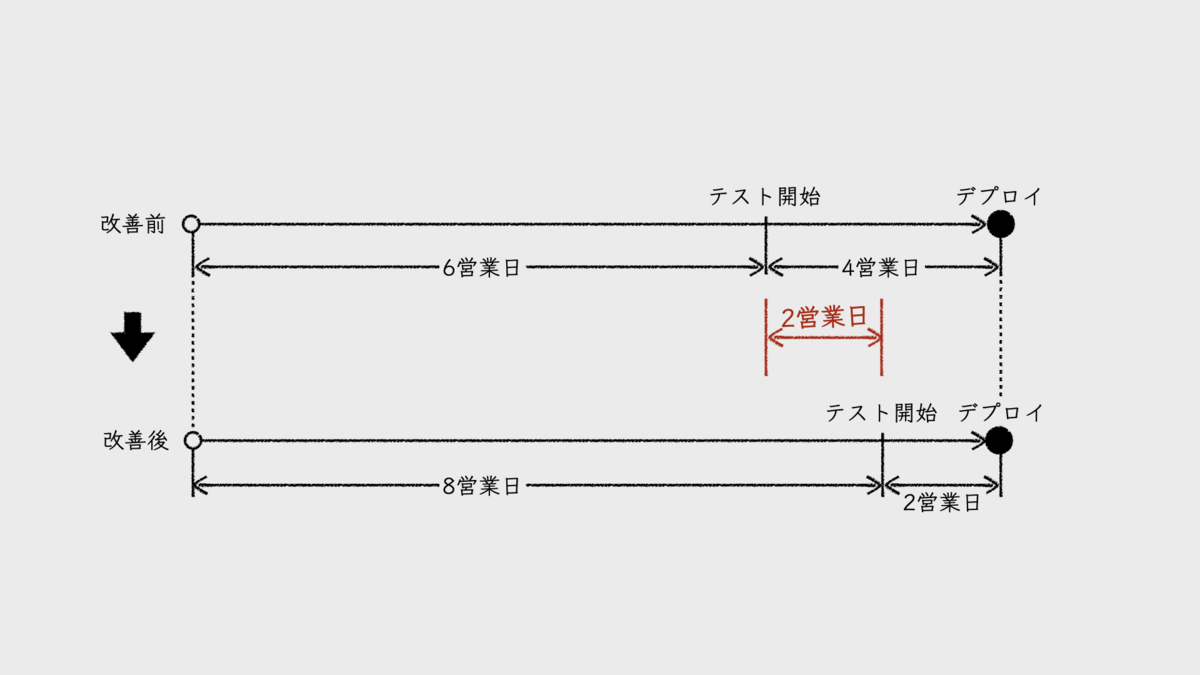
たとえば、2週間(10営業日)のイテレーションのうち、バッチ方式による製造フェーズのリードタイムが4営業日だったとしよう。6営業日が、開発項目フローごとの開発フェーズに使えるということだ。デプロイメントパイプラインの整備によって、製造フェーズのリードタイムが2日に改善されたとする。すると、削減された2営業日分が、開発項目フローごとの開発フェーズに使えるようになる。結果、フローの数が増えるのだ。
フローの数を増やすもう1つの方法は、開発フェーズの作業効率を高めることだ。Copilotを導入してコード実装を効率化したり、静的解析ツールを導入してコードレビューの手間を削減したりといったアイデアが考えられる。ただし、これによってフローの数が劇的に増えるかと言うと、そこまでは期待できないだろう。
バッチ方式からオンデマンドへ
フローを速くするという観点で言えば、「待ち時間の削減」という手段がまだ残されている。
たとえば、コード実装に1日、コードレビューに1日のフローであったとする。もし、コード実装を終えてから、コードレビューが開始されるまでに2日を要したらどうなるだろうか。このフローの開発フェーズのリードタイムは、4日となる。この待ち時間が0になれば、開発フェーズのリードタイムは2日に改善する。
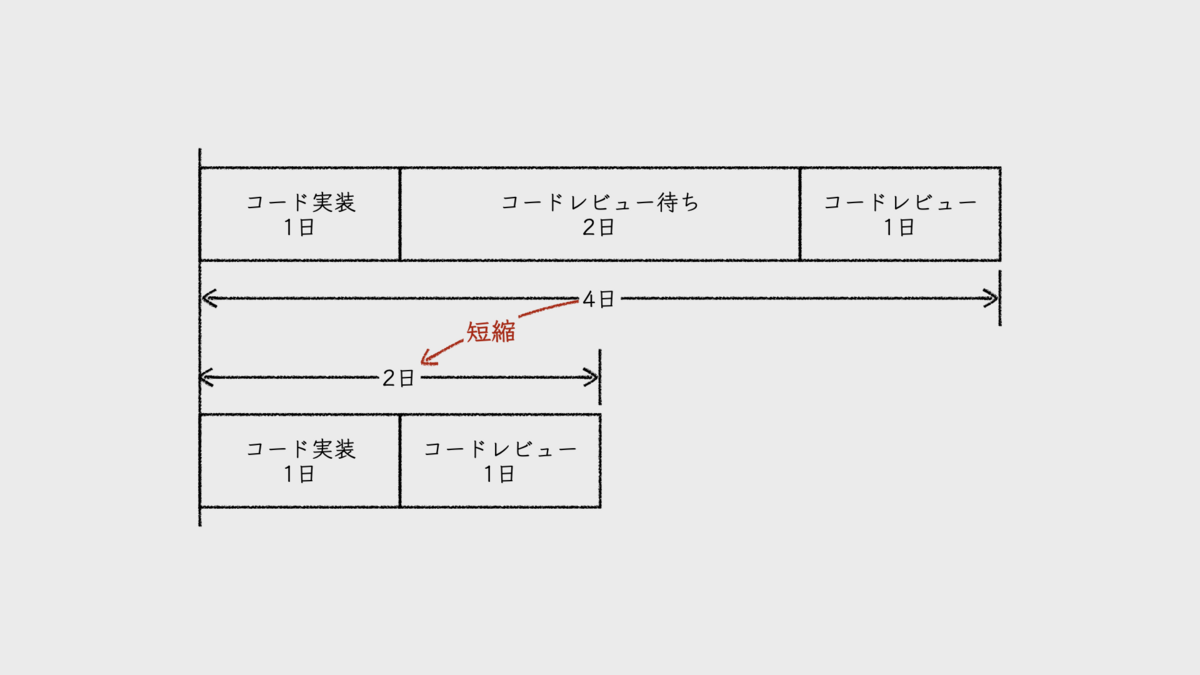
これは、一見すると、フローが早くなったように見える。しかし、イテレーションの中で発生するフローの待ち時間をいくら削減しても、バッチ方式である限り、実際にはフローは速くならない。削減された待ち時間が、デプロイまでのどこかの待ち時間として追加されるだけだ。
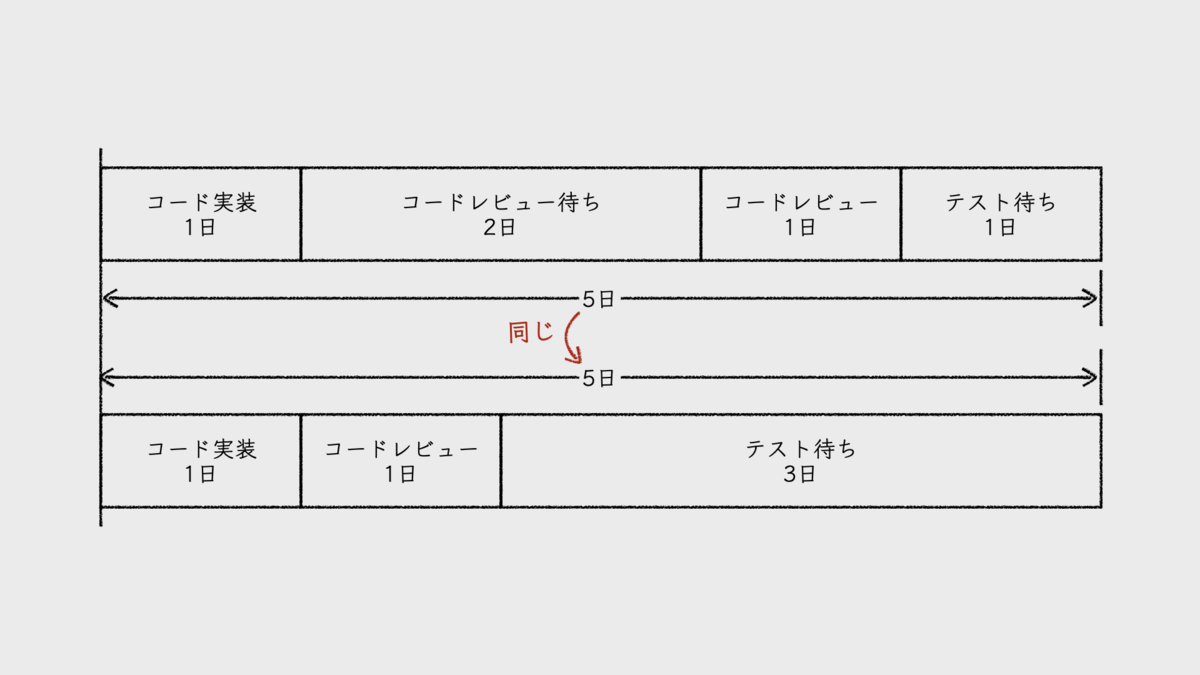
そこで、オンデマンド方式デプロイへの移行である。ハードルは高いが、パイプラインの整備も含め、これまでの取り組みにより、その下地はできているはずだ。
あとは、WIP制限といったプラクティスを活用して、開発フェーズのフローの待ち時間を削減することで、フローをより速くする。ここまでくれば、デプロイ頻度やリードタイムの計測に、大きな意味が出てくるはずだ。
目指すはバリューストリーム全体のフローを改善すること
フロー改善の目的が「素早く仮説検証をまわす」ことにあるなら、改善対象は開発チームの範囲だけにとどまらない。バリューストリーム全体がその対象となる。
しかし、その難易度はなかなかに高い。多くの組織において、生産性を求められる対象は、開発チームのプロセスの範囲だからだ。
その理由は、改善の目的が「素早く仮説検証をまわす」ことではなく、「より早く、より多くの機能をリリースする」ことにあるからだろう。その根底には、プロダクトに対するアイデアを、間違っているかもしれない「仮説」だとは捉えていない点にある。この思い違いから見直さなければならないだろう。