ArchUnitでアーキテクチャをテストする
ソフトウェアアーキテクチャには、依存関係のデザインという側面がある。その目的は多くの場合において、ソフトウェアの振る舞いに対する変更容易性を高めることではないだろうか。
ソフトウェアプロダクトは、そのライフサイクルを通して、繰り返し変更し続けられていく宿命にある。それがユーザーや顧客の要求であり、彼らの価値につながるからだ。そしてその提供には迅速さも求められる。依存関係のデザインは、これを実現するために組み込まれたソフトウェアの構造なのだ。
アーキテクトの悩みのひとつは、このような目的に基づいて自らがデザインしたソフトウェアの構造が、儚く崩れ去っていくことだ。アーキテクチャとは所詮はルールでしかない。開発チームが厳密にルールを守らない限り、望ましい構造を構築・維持することはできない。アーキテクチャは脆いのだ。それこそが技術的負債の一因でもある。
無償のJavaライブラリとして提供されているArchUnitは、そのルールをコードとして表現することを可能にした。テストオートメーションの一部としてビルドパイプラインに組み込めるということだ。これは、開発チームがデリバリするソフトウェアプロダクトの構造を、アーキテクトが描いたアーキテクチャに誘導し続ける大きな力となる。

私自身もまだ、ArchUnitの導入に向けた技術的な調査段階であるが、大いに可能性を感じている。本稿では、その過程で知ったArchUnitの機能について、ユーザーガイドを参考にしつつ紹介していく。
なお、本記事で対象としたArchUnitのバージョンは以下の通りとなる。
com.tngtech.archunit:archunit:1.0.0-rc1 com.tngtech.archunit:archunit-junit5:1.0.0-rc1
- ドキュメントとしてのテストコード
- 基本ステップ
- どんなことができるのか
- 定義済みの頻出ルール
- 既存プロダクトへの導入時に起こりうる大量のルール違反
- アーキテクチャメトリクスの計測
- テストの実行パフォーマンス
- 継続的な変更容易性の獲得による進化
ドキュメントとしてのテストコード
現実問題として、人が増えれば増えるほど、アーキテクチャとして描いたビジョンの浸透は難しくなる。その上、ソフトウェアエンジニアのスキルレベルが玉石混交となりやすい。少数精鋭の時のようにはいかない。以前の記事でも書いたが、様々な要因で積み重なる技術的負債の中でもこういった背景による負債こそが問題だと私は考えている。
次の図は、マーティン・ファウラー(Martin Fowler)による技術的負債の発生理由に関する四象限(TechnicalDebtQuadrant)を日本語化したものだ。上述した負債は、この四象限の左下にあたる「無謀で無自覚な負債」にあたる。

ArchUnitによるテストコードがあれば、意図的か無自覚かに関わらず、「無謀な負債」の蓄積を抑止・軽減できる。ルールに沿わない構造を持つ変更は、ビルドを失敗させるからだ。その原因を作った開発者は、当然ながらどんなテストが失敗したのか調べることになる。そうすることで、アーキテクチャがどのように定義されているのか学ぶことにもなる。
ここで発揮されるのが、ArchUnitで定義されたルールの可読性だ。次の例のように、英語の文章としてそのまま読めるメソッドチェーンを形成する構造となっている。classes() は、ArchRuleDefinition クラスから import static したメソッドだ。
ArchRule myRule = classes()
.that().resideInAPackage("..service..")
.should().onlyBeAccessed().byAnyPackage("..controller..", "..service..");
日本語で言えば、「service パッケージに存在するクラスは、controller および service パッケージからのみアクセスされるべき」といったところか。"..service.." は、com.example.myapp.service や com.example.myapp.service.customer などのパッケージ名にマッチするパターンだ。詳しくは PackageMatcher のドキュメント(コメント)に記載されている。
ところで、ArchUnitに関わらず、テストコードは何が良くて何が駄目なのかを明確に表現するドキュメントとなるが、なぜ良くて、なぜ駄目なのかまでは示さない。テストコードはあくまでもwhatを示すもので、そのhowがプロダクションコードだと言えるだろう。一人で開発する分にはそれだけでも十分であるが、複数人で開発するならやはりwhyが必要だ。テストコードやプロダクションコードだけに頼らず、コメントなどでwhyをしっかり残すことも必要だろう。
基本ステップ
ArchUnitでのコーディングの基本ステップは次の通りだ。
- 検査対象とするクラス群をインポートする
- ルールを定義する
- ルールを使い、インポートしたクラス群を検査する
JavaClasses classes = new ClassFileImporter().importPackages("com.example.myapp"); ArchRule myRule = classes().that().resideInAPackage("..service..") .should().onlyBeAccessed().byAnyPackage("..controller..", "..service.."); myRule.check(classes);
この例では、パッケージ名を指定してインポートしているが、他にもURLやJarファイルを指定することもできる。これらのバリエーションについては、ClassFileImporter クラスのメソッドを眺めると把握できるだろう。いずれにしても、最終的には importLocations(Collection<Location>) メソッドが呼び出されるようだ。
ちなみに、JUnit5でのテストは次のように書ける。
@AnalyzeClasses(packages = "com.example.myapp") public class ServiceTest { @ArchTest static final ArchRule service_only_be_accessed_by_controller_and_service = classes().that().resideInAPackage("..service..") .should().onlyBeAccessed().byAnyPackage("..controller..", "..service.."); }
こちらも @AnalyzeClasses アノテーションに用意された属性を見てみると、packages 以外にも packagesOf や locations などいくつかのインポート手段があるようだ。
どんなことができるのか
レイヤードアーキテクチャ(Layered Architecture)やクリーンアーキテクチャ(Clean Architecture)といった数々のソフトウェアアーキテクチャパターンが示すように、それらが持つ構造は、責務に注目してソフトウェアを論理的あるいは物理的な境界で分離し、高凝集で疎結合なモジュールやクラス、コンポーネントを実現するものだ。このようなアーキテクトによる構造定義に基づいて、開発者はソフトウェアプロダクトを実装し、成長させていく。
たいていのプログラミング言語は名前空間(namespace)を備えており、それをモジュールの単位として扱う。Javaで言えばパッケージ(package)がそれにあたる。ではモジュールたるパッケージに関する構造をArchUnitでどのように定義するのか、簡単な例をみてみる。
例1:foo パッケージ内のクラスは、bar パッケージ内のクラスに依存してはならない
noClasses().that().resideInAPackage("..foo..") .should().dependOnClassesThat().resideInAPackage("..bar..")
例2:foo パッケージ内のクラスに対するアクセスを、foo パッケージ自身と、bar パッケージに限定する
classes().that().resideInAPackage("..foo..") .should().onlyBeAccessed().byAnyPackage("..foo..", "..bar..")
例3:foo パッケージ内のクラスに対する依存を、foo パッケージ自身と、bar パッケージに限定する
classes().that().resideInAPackage("..foo..") .should().onlyHaveDependentClassesThat().resideInAnyPackage("..foo..", "..bar..")
この、例2と例3の違いは、「アクセス」と「依存」だ。例2では、フィールドやメソッド、コンストラクタに対するアクセスのみ禁止しているだけだが、例3では依存関係を作ること自体を禁じている。このような細やかな制御が可能である点も気が利いている。
もちろん、パッケージを指定したルールだけではなく、次の例のようにクラスを指定したルールを記述することもできる。
例4:Foo に assignable なクラスに対する依存を、foo パッケージと、bar パッケージに限定する
classes().that().areAssignableTo(Foo.class) .should().onlyHaveDependentClassesThat().resideInAnyPackage("..foo..", "..bar..")
例5:名前が Foo で終わるクラスは、foo パッケージ内に入っていなければならない
classes().that().haveSimpleNameEndingWith("Foo") .should().resideInAPackage("foo")
以上のように、多くのルールは次の形式で定義される。
classes that ${PREDICATE} should ${CONDITION}
PREDICADEとCONDITIONのバリエーションについてはそれぞれ、ClassesThat インタフェース、ClassesShould インタフェースが持つメソッドを見ると良い。ここで例に挙げた表現がほんの一部でしかないことがわかる。
これらの例ではいずれも classes() を使ってクラスを対象にしたルールを表現していたが、次の例の methods() のようにメソッドを対象にしたり、フィールドやコンストラクタなども対象にすることができる。これらのバリエーションは、ArchRuleDefinition クラスのメソッドとしてまとまっている。
例:foo パッケージ内にあるクラスの public メソッドは、@Bar アノテーションが付けられていなければならない
methods().that().arePublic().and().areDeclaredInClassesThat().resideInAPackage("..foo..") .should().beAnnotatedWith(Bar.class);
個人的な印象として、Javaでの厳密なモジュール化(modulization)の実現は難しいと感じている。モジュールレベルでのカプセル化を実現するために、公開する振る舞いを制限しようにもアクセス修飾子だけでは不十分だったし、それを補おうとするとクラス同士の関係やコードが複雑になり過ぎてしまう。苦労して実現したとしても、モジュールユーザーによってコードレベルで破られることもある。いずれにしても、何らかの形でカプセル化が破られてしまうと、モジュールへの変更に対するモジュールユーザーへの影響が拡大してしまう。それらを防ぐ防御策はこれまでずっと、文書と規律という不確実な手段にゆだねられてきた。
ArchUnitは、カプセル化の堅持をテストコードによって保証する。規律に強制力が伴ったのだ。カプセル化を追求し過ぎることによる複雑化の軽減も期待できそうではないか。
定義済みの頻出ルール
ArchUnitの主要なAPIは、Core, Lang, Libraryの3つのレイヤーに分かれている。CoreレイヤーのAPIは、基本的な機能を提供している。LangレイヤーのAPIは、ここまで例に挙げたような、アーキテクチャを簡潔に定義するためのルール構文を提供している。そしてここで取り上げるLibraryレイヤーは、よく使われるであろうパターン化されたルールを簡単に扱うためのAPIを提供している。
例えば、非循環依存関係の原則(ADP, Acyclic Dependencies Principle)を徹底したいならば、次のように書くだけだ。
slices().matching("com.example.myapp.(*)..")
.should().beFreeOfCycles()
この例では、com.example.myapp 配下におけるパッケージ間の循環依存を検出できる。slices() は、SlicesRuleDefinition クラスのメソッドを import static したものだ。
DependencyRules クラスの定数 NO_CLASSES_SHOULD_DEPEND_UPPER_PACKAGES も興味深い。これは、下位階層パッケージのクラスが上位階層パッケージに直接依存することを禁止する ArchRule だ。
他にも、GeneralCodingRules クラスや ProxyRules クラスにも定数やメソッドがいくつか定義されている。NO_CLASSES_SHOULD_USE_JODATIME や USE_JODATIME など、細かいがなかなか気が利いている。
おそらく最も注目すべきなのは、典型的なアーキテクチャパターンが、Architectures クラスに定義されていることだろう。
例:レイヤードアーキテクチャ(Layered Architecture)
layeredArchitecture()
.consideringAllDependencies()
.layer("Controller").definedBy("..controller..")
.layer("Service").definedBy("..service..")
.layer("Persistence").definedBy("..persistence..")
.whereLayer("Controller").mayNotBeAccessedByAnyLayer()
.whereLayer("Service").mayOnlyBeAccessedByLayers("Controller")
.whereLayer("Persistence").mayOnlyBeAccessedByLayers("Service")
説明するまでもないコードだが、見ての通り3つのレイヤーを定義した上で、それぞれ閉鎖レイヤーにするか、開放レイヤーにするかといったレイヤーの分離を定義している。
例:オニオンアーキテクチャ(Onion Architecture)
onionArchitecture()
.domainModels("com.myapp.domain.model..")
.domainServices("com.myapp.domain.service..")
.applicationServices("com.myapp.application..")
.adapter("cli", "com.myapp.adapter.cli..")
.adapter("persistence", "com.myapp.adapter.persistence..")
.adapter("rest", "com.myapp.adapter.rest..");
こちらも見た通りだ。アプリケーションコア(application core)となるドメインモデル(domain model)、ドメインサービス(domain service)、アプリケーションサービス(application service)の3レイヤーを定義した上で、アダプタ(adapter)を定義している。
1.0.0-rcでのサポートは、レイヤードアーキテクチャとオニオンアーキテクチャの2つのみのようだが、今後の追加に期待できそうだ。
既存プロダクトへの導入時に起こりうる大量のルール違反
レガシーなソフトウェアプロダクトに対してArchUnitを使い始めれば、おそらく大量のルール違反が出てしまうだろう。そういったケースでの対応方法も用意されている。
そのひとつは、archunit_ignore_patterns.txt という名前のファイルをクラスパスに置くことだ。このファイル内に行区切りで記述された正規表現にマッチした違反は無視されるようになる。
例えば次のように書けば、com.example.myapp.foo.Foo クラスに関する全ての違反が無視され、失敗ではなく成功が報告されるようになる。
.*com\.example\.myapp\.foo\.Foo.*
ただこの方法では、無視された違反を反復的に改善していくといったアプローチが取りづらい。改善の都度、対象となる違反が検出されるように正規表現を書き換える必要があるからだ。
そこで、もうひとつの手段である FreezingArchRule を使う。FreezingArchRule は、報告された違反を ViolationStore に保存する。これによって、新たな違反のみを報告し、既知の違反は無視するようになる。そして、修正された違反は、ViolationStore から削除される。
FreezingArchRule の良いところは、ViolationStore での保存先としてテキストファイルを使用する点だ。このファイルをバージョン管理すれば、レガシーシステムの継続的な改善を追跡できるようになる。
使い方は次のように、対象とする ArchRule を FreezingArchRule でラップするだけだ。
ArchRule rule = FreezingArchRule.freeze(classes().should()..省略..);
ソフトウェアプロダクトを漸進的に成長させていけば、変化への適応や、学習による改善によって、ソフトウェアプロダクトの構造を変化させるべくルールを書き換えることもある。そのようなケースでも、FreezingArchRule が役立つだろう。書き換えたルールが大きな変更であれば、プロダクションコードを一気に書き換えることはできず、時間を書けて反復的に改善することになるからだ。これは、技術的負債の四象限の右下にあたる「慎重で無自覚な負債」だと言える。
アーキテクチャとは「変化させられないもの、変化させにくいもの」とされてきたが、この右下の象限が示すように、変化の必要性は生じる。進化的設計(evolutionary design)や進化的アーキテクチャ(evolutionary architecture)には、これが背景にあるのだろう。繰り返し変更を加えるソフトウェアプロダクトに関わっていれば経験的に気付くように、アーキテクチャが変化しないことを前提にしてしまうと、そのソフトウェアプロダクトの変更容易性は絶対的にも相対的にも低下していくことになる。このような事態を能動的・積極的に回避する用途としても、ArchUnitの活用を検討したいところだ。
アーキテクチャメトリクスの計測
静的コード解析ツールで計測するコード品質に関するメトリクスと同様に、アーキテクチャにもメトリクスがある。例えば、書籍『Clean Architecture』では、著者ロバート・マーチン(Robert C. Martin)による次のメトリクスが紹介されている。
| メトリクス | 説明 |
|---|---|
| ファン・イン(fan-in) | 依存入力数。コンポーネント内のクラスに依存している外部のコンポーネントの数 |
| ファン・アウト(fan-out) | 依存出力数。コンポーネント内にある、外部のコンポーネントに依存しているクラスの数 |
| I(Instability) | 不安定さ。 |
| A(Abstractness) | 抽象度。 |
| D(Distance) | 距離。 |
ArchUnitでは次のように、ComponentDependencyMetrics を使って簡単に計測できる。ここで、afferent couplingはファン・イン、efferent couplingはファン・アウトの旧名称だ。
Set<JavaPackage> packages = classes.getPackage("com.example.myapp").getSubpackages(); MetricsComponents<JavaClass> components = MetricsComponents.fromPackages(packages); ComponentDependencyMetrics metrics = ArchitectureMetrics.componentDependencyMetrics(components); int fanIn = metrics.getAfferentCoupling("com.example.myapp.component"); int fanOut = metrics.getEfferentCoupling("com.example.myapp.component"); double i = metrics.getInstability("com.example.myapp.component"); double a = metrics.getAbstractness("com.example.myapp.component"); double d = metrics.getNormalizedDistanceFromMainSequence("com.example.myapp.component");
その他にどのようなアーキテクチャメトリクスがArchUnitでサポートされているかは、ArchitectureMetrics クラスから辿ることができる。
テストの実行パフォーマンス
少し気になるのは、テスト対象とするクラスのインポートに関するパフォーマンスだ。これについてはまだ詳しくは調べていないが、インポートされたクラスのロケーションごとにキャッシュされるようだ。同一のURLやJarからインポートしたクラスであれば、テストクラス間で再利用されるということだろう。
ちなみにこれはデフォルトの挙動で、次のように CacheMode.PER_CLASS を指定してやることで、テストクラス単位でのキャッシュに切り替えることもできる。
@AnalyzeClasses(packages = "com.example.myapp", cacheMode = CacheMode.PER_CLASS) public class FooTest { ...
いずれにしても、ArchUnitによるアーキテクチャの本格的な自動テストは、多少の実行時間を要しそうだ。ビルドパイプライン上では、通常のユニットテストやスモールテストより後ろのステージに配置すべきかもしれない。
継続的な変更容易性の獲得による進化
ArchUnitによって、ソフトウェアアーキテクチャとしてデザインされた構造は「テスト容易性(testability)」を手に入れた。そのインパクトは大きい。その恩恵は、開発者が書いたコードを検証することだけにとどまらない。
テストとはすなわち、フィードバックを得ることでもある。ArchUnitで書いたテストコードは、ソフトウェアプロダクトの構造に対するフィードバックループを形成し、そのサイクルを高速化するはずだ。TDDを思い起こすと分かるように、テストコードによる短期間のフィードバックは、実装だけでなく、設計自体の変更も促す。TDDほど短期間でなくとも、少なくともこのプロセスはテストファーストだと言える。構造に関するテストコードの存在は、構造設計そのものの変更も促すのではないだろうか。そしてそれが、「変化させられないもの、変化させにくいもの」とされてきたソフトウェアアーキテクチャに変更容易性をもたらす。
テキストや図でドキュメント化された開発ガイドラインをこまめにアップデートする組織はあまり聞かないが、コード化されたルールならどうだろうか。テストで検出されず、コードレビューで頻繁にコメントされるような指摘事項は、すぐにテストコードとして書いてしまえば良い。逆に、テストによって違反として検出されることが多いルールが、実は現状にそくしたものではなく、変更容易性を悪化させているのだと気付くこともあるだろう。このようにして追加、変更されたルールは、即座にテストスイートとして機能する。そしてまたフィードバックを得る。ドキュメントベースのガイドラインでは、そうはいかなかった。変更箇所を開発者が読んで理解しない限り、機能しないからだ。
テスト容易性を得たアーキテクチャはもはや、静的なものではなくなる。フィードバックループの中でアーキテクトと開発チームが絶えず学習し、その成果としてルールが見直されることで、継続的に変更容易性を獲得し続ける。これこそが、「進化的(evolutionaly)」あるいは「進化可能性、進化容易性(evolvability)」と呼べるものではないだろうか。
エンジニアリングマネージャーという役割にどう向き合うか
エンジニアリングマネージャーとしての日々の仕事にやりがいを感じられない。そういう人は多いのではないか。
「マネジメント業務の中では達成感を得られず、自身の成長も感じられない」「会議や調整ばかりの毎日で、週末に一週間を振り返ってみても、明確なアウトプットもなく、自分が一体何をしていたのか思い出せない」といった声をきく。
やりがいを感じられないのは、やったことに対する明確な手応えを感じられないからだろう。エンジニアとしてソフトウェア開発に邁進していた頃とは違い、マネージャーとはそういうものだと半ば諦めてしまっているのかもしれないが、その認識は正しくない。ソフトウェアエンジニアがソフトウェアを開発するように、エンジニアリングマネジャーは、エンジニアリング組織を開発している。マネジメントをそう捉えると、様々な見え方が変わる。手応えも感じられるようになる。
手応えとは、言い換えれば「フィードバック」だ。ソフトウェアデリバリでは変更に対してフィードバックを得ることで学び、プロセスを素早く適応させる。このフィードバックループによって、ソフトウェアの価値を高め続ける。マネジメントにおいて手応えを感じられないのだとすれば、それは、エンジニアリング組織の価値を高めるための「変更」に取り組めていないのかもしれない。日々の業務に忙殺され、何をすべきか思考する時間を奪われてしまっているのではないか。
高めるべきエンジニアリング組織の価値とは何だろうか。それは、優れたソフトウェアを作り出す能力だと私は考える。そのためにはもちろんエンジニア一人ひとりの技術力向上も必要であるが、適切な組織構造やプロセスも必要となる。そして、コンウェイの法則によって組織構造に強く影響を受けるアーキテクチャについても考えなければならない。
それこそ、バックログを作り、優先順位を付けて、エンジニアリング組織の変更に取り組むのも良いだろう。その変更が成功したかどうかは、あらかじめ決めておいたメトリクスによって判断する。意図した通りにメトリクスの値が変化したならば、最高の達成感を得られるだろう。そうならなくても学びを得られる。もちろん全てを定量化できるわけではないので、そういったケースでは組織内外に変更結果についてヒアリングすれば良い。
エンジニアリング組織のマネジメントとは、まさにエンジニアリング組織に対するエンジニアリングだ。そういった観点から、エンジニアはそもそもマネージャーに向いているのではないだろうか。
日々の業務に追われ過ぎると、組織について考える時間を取れない。組織改善に向けたバックログにアイテムを追加することすらできない状態に陥る。マネージャーには考える時間と、考えたことを実行し、その結果を評価する時間が要る。
エンジニアリングマネージャーとしての日々の仕事にやりがいを感じられないのなら、忙殺される毎日から抜け出すことが、まず最初にやるべきことになるだろう。エンジニアリングマネージャーとして、エンジニアリング組織の改革・改善に没頭できたなら、こんなにやりがいのある仕事はないと感じられると思う。
エンジニアリングマネージャーとしてのミッション
ソフトウェアプロダクト開発領域を預かるエンジニアリングマネージャーとして、あなたのミッションは何であるか。そう問われれば迷わず、組織としての「プロダクト開発能力の差異化」だと答える。これはもちろん私個人の見解ではあるが、受託開発組織のマネジメントを離れ、プロダクト開発組織を主としてマネジメントするようになった10年以上前から変わらない。
「プロダクトの差異化ではなく?」と聞き返されることも多い。ユーザーやビジネスにとって価値ある優れたプロダクトやフィーチャを作り出すことはもちろん第一級のミッションだ。そうであっても、そこで得られた成功が "偶然" であるなら組織としての持続性がない。「プロダクト開発能力の差異化」とは、そういった成功に再現性を持たせることを意味する。
- 組織としての「プロダクト開発能力の差異化」
- 開発能力はデリバリパフォーマンスとして表れる
- 組織構造とプロセス、アーキテクチャを進化させ続ける
- 組織構造でコミュニケーションコストを最小化する
- プロセスにフィードバックループを多重に織り込む
- アーキテクチャによってデプロイとテストの容易性を高める
- 保守性を高める技術を学ぶ
- 組織を動かすのは人である
組織としての「プロダクト開発能力の差異化」
そもそも優れたプロダクトやフィーチャは他社に真似されやすい。先発優位が長続きする市場はその数を減らしつつある。競争優位はもはや一時的で、持続しないことを前提に考えるべきだろう。経営学者のリタ・マグレイス(Rita McGrath)は、一時的な競争優位を同時並行的に確立し続けることが、長期間にわたるリードに繋がると説いた。優れたプロダクトやフィーチャを作り出して練り上げるだけでなく、更に新たな価値を生み出す。何度も何度も創造する。ここに、成功への再現性が要る。
この「再現性」というものは、組織が経験を積み重ね続けて得た能力(スキル)だ。それは、組織の存続年数に比例するものではない。ソフトウェアデリバリという実務の遂行に追われているだけでは備わらない。組織レベルでの経験学習サイクルをもって備わるものだ。
「カイゼン」を文化にまで落とし込んだトヨタに代表されるように、学習が文化として定着した組織は強い。この観点では、学習する組織を作り上げることがミッションであるとも言える。
優れたプロダクトやフィーチャは真似されやすくても、こうして組織に備わった能力というものは、そう簡単に真似されるものではない。
開発能力はデリバリパフォーマンスとして表れる
では、肝心な「組織としてのプロダクト開発能力」とは何であるか。ソフトウェアエンジニアリングを担う組織にとってのそれは、ソフトウェアデリバリのパフォーマンスだ。ニコール・フォースグレン(Nicole Forsgren)らの調査によって、ソフトウェアデリバリのパフォーマンスは、組織全体のパフォーマンスに影響する予測要因であり、両者は正の相関関係にあることが明らかにされた。ソフトウェアエンジニアがそれまで経験的に感じていたことが、正しかったと調査によって示されたのだ。
ソフトウェアデリバリのパフォーマンスは、4つのメトリクスで表される。デプロイの頻度(deployment frequency)、変更のリードタイム(lead time for changes)、平均修復時間(time to restore service)、変更失敗率(change failure rate)だ。この4つのキーメトリクスこそ、開発チームが経験を積み重ねて獲得する能力を観測するものだ。
Accelerate State of DevOps Reportでは、調査結果に基づいてこれらのメトリクスをEliteパフォーマンスからLowパフォーマンスまで4段階に分類している。自チームのスコアと比較することで、優位性を把握することが可能となる。もちろん、開発チームはそれぞれ置かれた状況や事情が異なる。必ずしもこのパフォーマンス分類がそのまま当てはまるわけではないが、参考にはなるはずだ。

組織構造とプロセス、アーキテクチャを進化させ続ける
組織としての「プロダクト開発能力の差異化」を実現し、高めていくためには、組織改革は継続的なものとなる。終わりがなく、永遠に完成することはない。進化していくように適応を繰り返す。
そこでの改革対象は、組織構造とプロセス、そしてアーキテクチャの3つを常にセットで考える。取り組む順番は組織構造、プロセス、アーキテクチャの順が良い。組織構造およびプロセスが、アーキテクチャに影響を与えるからだ。これはコンウェイの法則としておなじみだろう。
また、アルフレッド・チャンドラー(Alfred Chandler)の「組織は戦略に従う」という言葉のように、戦略に合わせて組織設計から始めることが自然にも感じる。組織設計には逆コンウェイ戦略を用い、その後に控えるアーキテクチャの変更を連動させる。

「組織は戦略に従い、システムは組織に従う」とでも言えば良いだろうか。ビジネスを取り巻く内外の状況変化に応じて戦略は変化する。その変化に対し、組織を柔軟に変化させ、アーキテクチャを進化させ続けるということだ。
組織構造でコミュニケーションコストを最小化する
組織をどのようにチーム分割するか。その結果が組織構造となる。チームを組織にとってのコンポーネントだと捉えてみると、設計の方向性が見えてくる。
ソフトウェアコンポーネントと同様に、組織コンポーネントたるチームも高凝集であるべきで、かつ、チームは互いに疎結合であるべきだ。そうすれば、それぞれのチームのソフトウェアデリバリは互いに干渉することがない。ソフトウェアの変更もデプロイも、他チームや誰かの助けや承認を得ること無く、チームが独立して実行可能になる。
これについては以前にも『開発組織を分散モノリスにしないチーム分割と協働のデザイン - mtx2s’s blog』というタイトルでブログ記事を書いた。
高凝集で疎結合な組織は、チーム内でのコミュニケーションが密(高帯域幅)に、チーム間でのコミュニケーションが疎(低~中帯域幅)になる。これは、組織内のコミュニケーションコストを最小化するとともに、このコミュニケーション構造がソフトウェア設計にも良い影響をもたらす。

『チームトポロジー』の著者であるマシュー・スケルトン(Matthew Skelton)らに言わせれば、「多くの組織はいつでもコミュニケーションは多いほうがよいと考えるが、実際にはそうではない」ということだ。『アジャイルな見積りと計画づくり』の著者としても知られるマイク・コーン(Mike Cohn)も、ブログ記事 "Nine Questions to Assess Team Structure" にて、「チーム間のコミュニケーションパスの数を最小化する構造になっているか?」と問うている。
組織構造を設計するにあたっては、エリック・エバンス(Eric Evans)のドメイン駆動設計(DDD, Domain-Driven Design)が役立つ。ソフトウェアプロダクトが扱う対象領域を適切にコンテキストに分ける。そしてこのコンテキストをもとに、どのようにチーム分割するかと、それぞれの責務が形作られる。その結果は、戦略に影響を受けるはずだ。こうして作られたチームの多くはストリームアラインドチーム(stream-aligned team)となり、それぞれが独自のバリューストリームに組み込まれることになるだろう。
プロセスにフィードバックループを多重に織り込む
ソフトウェアデリバリのサイクルを重ねる度にチームが生み出す成果と言えば、プロダクトバックログアイテムを実現したインクリメント(フィーチャや機能)をまっさきに思い浮かべる。チームが成果をそのように捉えているならば、そのチームは優れたプロダクト開発能力を得ることはできないだろう。
チームがコミットすべきはその先、つまり、インクリメントのリリースによって、優れたユーザー体験を生み出すことだ。それがユーザー価値となり、ビジネス価値につながっていく。
このような優れたユーザー体験を生み出す開発能力は、どのようにして備わるのだろうか。
優れたチームは、デリバリサイクルを重ねる過程で、プロダクトナレッジとプロジェクトナレッジという、チームの開発能力に対するインクリメントを作り出す。プロダクトナレッジは、「何を(what)作れば良いか」という目標不確実性を低減し、チームを正しいプロダクト価値に近づけていくためのナビゲーション精度を高める。プロジェクトナレッジは、「どう(how)作れば良いか」という方法不確実性を低減し、ソフトウェアデリバリにおける様々なプロセスを洗練させる。

経験に基づいて高濃度で高品質なナレッジを抽出するには、フィードバックの獲得は欠かせない。フィードバックループのサイクルが短いほど、その純度は高まる。アジャイル開発手法やDevOps、リーン開発は、プロセスにフィードバックループが組み込まれている点が優れている。
「スプリントレビュー」は、数日から数週間単位でのフィードバックだ。デプロイ頻度や変更のリードタイムを改善していく目的のひとつがこのフィードバックループの高速化だと考えると良い。「テスト駆動開発」は数十秒から数分単位のフィードバックループだ。「継続的インテグレーション」や、「ユーザーフィードバックの収集と活用」もフィードバックループだ。

上図は、VersionOneのポスター(原典は既に存在しない)をもとに書き起こしたものだ。このように、大小さまざまなフィードバックループを幾重にもプロセスに織り込む。それが、ソフトウェアデリバリのパフォーマンスを大きく左右するほどのナレッジの継続的な獲得につながっていく。
アーキテクチャによってデプロイとテストの容易性を高める
ここで言うアーキテクチャとは、ソフトウェアがどのようにコンポーネント分割されているかと、それらの依存関係を指す。コンポーネントとは、『Clean Architecture』で言うところの「デプロイの単位」であり、「システムの一部としてデプロイできる、最小のまとまり」を指す。
アーキテクチャで注力すべきは、コンポーネントのデプロイとテストの容易性だ。フォースグレンらは、著書『LeanとDevOpsの科学』の中で、デプロイとテストの容易性について次のように定義している(定義内の「アプリケーション」を「コンポーネント」として読み替えて欲しい)。
- テストの大半を、統合環境を必要とせずに実施できる
- アプリケーションを、それが依存する他のアプリケーションやサービスからは独立した形で、デプロイまたはリリースできる(そして実際にもデプロイまたはリリースしている)
この定義に更に、チームの凝集性に関する3つめの要素を加えたい。
これら3つに当てはまるならば、チームは高い独立性を持ってソフトウェアデリバリを遂行できる。逆に言えば、この定義に当てはまらないチームは、独立性が低く、ひとつのプロダクトバックログの実現のために、他のチームの力を借りなければならない事態が頻発するということだ。これではパフォーマンスを発揮できるはずがない。
忘れてはならないのは、組織構造やプロセスの変化がバリューストリームの流れを変え、それが各チームのプロダクトバックログの内容を特徴づけるということだ。つまり、コンテキスト境界に変化が起きているのだ。組織構造、プロセス、アーキテクチャをセットで変えていく必要性は、ここにある。
しかし、経験から言って、組織改革を進める上でアーキテクチャの変更が議題に挙がることはまれだ。組織構造、プロセスをどう変えるか。集中的に議論されるのはそればかりだ。
それはそうだろう。組織構改革にアーキテクチャとの関係性を見出すことは難しい。当たり前のように、アーキテクチャだけが取り残されてしまう。改革前の組織によって形作られたアーキテクチャが、新しい組織と上手く噛み合うとは限らない。
新しい組織構造やプロセスにあわせ、アーキテクチャが理想的な形へと自然に変化することなど期待できない。新しいアーキテクチャを仮説として持ち、それをフィードバックループの中で漸進的に進化させながら形にしていく。その仮説は、ドメイン駆動設計を詳細化する中で、組織構造とプロセスにも反映されている。これこそが、逆コンウェイ戦略だろう。
保守性を高める技術を学ぶ
ソフトウェアプロダクト開発というものは、繰り返し繰り返しソフトウェアを変更する活動だ。この「変更する」という活動を中心にソフトウェアデリバリを見つめ直すと、「変更しやすさ」がデリバリパフォーマンスのキーファクターのひとつであると気付く。変更しにくいソフトウェや変更できなくなったソフトウェアは価値を失い、競争力を失う。プロダクトをそのような状況に追い込んだ組織に、優れたプロダクト開発能力があろうはずがない。
変更しやすさ、すなわち変更容易性(modifiability)は、理解容易性(understandability)、テスト容易性(testability)と並んで保守性(maintainability)を構成する。バリー・ベーム(Barry Boehm)らの定義するこの3つの品質特性は、互いに関連しあっている。理解容易性を高めれば、変更容易性も高まる。テスト容易性が高いコードは、理解容易性も変更容易性も高いと言われる。

コードの保守性を高めるためには、リファクタリングが欠かせない。リファクタリングと言えば、いわゆる「レガシーコード」と呼ばれる既存コードに対する技術的負債を返却する行為というイメージがあるが、実際には新しいコードを書くにも必要な技術だ。それは、ケント・ベック(Kent Beck)がエクストリーム・プログラミングと共に広めたテスト駆動開発にリファクタリングが組み込まれていることからも分かる。
ここで私は、リファクタリングを「技術」と言った。マーティン・ファウラー(Martin Fowler)の著書『リファクタリング』や、マイケル・フェザーズ(Michael Feathers)の著書『レガシーコード改善ガイド』などからも分かるように、リファクタリングはスキルなのだ。そしてリファクタリングの実践にはテストコードが付きものであり、その手法たるテスト駆動開発もまたスキルだ。保守性を高めるためには、この2つのスキルを伸ばす必要がある。
当然ながら、テスト駆動開発やリファクタリングの技術的な基礎となるのは、オブジェクト指向といったプログラミングパラダイムへの深い洞察と理解だ。そしてそこから優れたアーキテクチャが生まれる。
これらのスキルや知識は、必要に迫られてのコードリーディングや、ペアプロなどによるスキルトランスファーといった、OJTでも獲得できる。しかしここにOFF JTを加えることで、その効果はより高められる。良い意味で意識の高いチームは、技術書の読書会を定期的に開いたり、技術研修に参加したり、LT大会でチーム内外の知識の共有を促進している。
ソフトウェア開発組織は、日々のソフトウェアデリバリ業務に忙殺されがちだ。実務外のこのような取り組みはなかなか導入しづらいだろう。しかし、だからこそスキル向上に力を入れられたならば、「差異化」につながるのだ。
組織を動かすのは人である
「組織は戦略に従う」とは言ったものの、組織を動かすのは人である。彼らは、戦略やミッションに理解と共感を示し、誇りを持って業務を遂行できているだろうか。こういった従業員エンゲージメントは、その高さがパフォーマンスに影響を及ぼす。
従業員エンゲージメントはeNPSで定点観測可能であるが、そのスコアの上下が何に起因しているか正確に分析することは難しい。その深層を1on1を通して汲み上げようと試みるも、対策可能なほどに具体的な問題にまで焦点を絞り込むことがなかなかできない。そもそもeNPSの被観測者本人でさえ明確には理由が答えられないからだ。
マネージャーがコーチングスキルを高めていけば解決しそうではあるが、これは結局、1on1やコーチングをマネージャーによる情報収集の手段としている点で適切なアプローチとは言い難い。そもそも、マネージャーが問題を把握し、施策を展開するより、チームで話し合って問題解決に取り組む方が実情に即したものになりやすく、達成感も得られやすいのではないだろうか。それこそが自律的な組織ではないか。マネージャーとして、そこでチームから出てくる相談に協力は惜しまない。
ジェフ・サザーランド(Jeff Sutherland)が、チームによる「幸福度の計測」と呼ぶ手法を著書『スクラム』で紹介している。チームがスプリントレトロスペクティブの度に「どうしたらより幸せになれるか、満足できるか」を問う3つの質問にメンバー全員が答え、チーム全体で改善に取り組むというものだ。これを続けて幸福度を上げていくことでベロシティが3倍になったと言う。
また彼は、チームのメンバーを実際に幸せにする要素とは、主体性、スキルアップ、目的意識だと断言している。さらにこれらをそれぞれ「自分の運命を自分でコントロールできること」「何かについて自分が上達しているという実感」「自分より大きな何かに力を尽くしているという感覚」と言い換えている。エンジニア経験があれば、この言葉に共感できるのではないだろうか。これらの価値を尊重し、チームが自己組織化していく文化の醸成にこそ、マネージャーは力を尽くしたい。
戦略やミッションへの理解と共感は、目的意識を醸成するだろう。それが、組織構造とプロセスの本質を捉えた行動や判断につながる。実践に基づくプロダクトナレッジとプロジェクトナレッジの獲得や、学びの文化は、スキルアップとなってデリバリパフォーマンスを向上させる。チームによる幸福度の計測は、主体性を高め、チームを自己組織化させる。
「成功への再現性」という点では、人材育成や組織内の流動性も欠かせない。人の価値観は変わりくいからだ。長期間、顔ぶれが変わらず役割が固定化した組織は、価値観が固定して新しいものを生み出しにくくなる。属人化も起きるだろう。だからこそ新しい世代の台頭や、新たな文化の流入が必要だ。このサイクルには、我々のようなマネージャーも含まれている。
こうして絶え間ない進化を続ける組織こそ、「プロダクト開発能力の差異化」を手にする組織なのだ。
組織設計の失敗に見るソフトウェア開発への悪影響
問題を抱えるソフトウェア開発組織を観察すると、その根本原因が組織設計にあると気付くことも多い。組織の構造的な歪みがまるで力場を形成するかのように、そこに配置された様々な要素に作用し、悪影響を及ぼしている。
組織設計のまずさから生じる問題というものはとらえ難く、理解し難い。その問題に気付かないから、真っ先に矛先がソフトウェアエンジニアリング領域へ向いてしまい、開発プロセスやソフトウェアアーキテクチャの改善を繰り返すが大きな効果が得られない。効果があったとしてもそれは一時的で、気付けば元に戻っている。
コンウェイの法則を思い出せばその従属関係に頷けるはずだが、多くの現場ではこういったソフトウェアエンジニアリング領域に閉じた施策に終始しがちではないだろうか。
以下に挙げる3タイプの組織問題は、ソフトウェアエンジニアやマネージャーとして私が実際に経験したいくつかの事例をタイプ別に集約したストーリーだ。複数事例の問題点を凝縮したため極端なストーリーになってしまった感は否めないが、その方が問題が強調されて理解しやすい。ここには問題の解決策が書かれていないが、失敗を回避するヒントや気付きを得るぐらいの価値はあると期待している。
プロジェクトチームとリソースプール
プロジェクトチームと呼ばれる体制は、どうやら多くのケースで"直感的に"採用される選択肢のようだ。プロジェクトの性質に適した人材をアサインできる柔軟さを持ち、それ故にクロスファンクショナルであり、スピード感がある、と。少なくともこの体制を選択する人たちは、そう信じているようだ。
これが全くの間違いだとは思わないが、最も基本的な制約と前提が考慮されていない。人材は有限であることと、いつだって多くのプロジェクトが並走しているということだ。
これらの事実から、プロジェクトチームがいわゆる「ドリームチーム」になることなど奇跡だ。プロジェクトマネージャーは、何とか頭数だけ揃えた体制でプロジェクトをスタートせざるを得ない。これで上手くやっていけるのか不安になる。やはりチームには、優秀なエンジニアにも参加して欲しい。
優秀なエンジニアは年中引っ張りだこだ。同時にいくつものプロジェクトを掛け持ちしている。そんな彼らから稼働時間を搾り取っても、せいぜい10%や20%程度が良いところだろう。その短い時間を使うことでさえ、彼らのスケジュールに合わせなきゃいけない。これがクリティカルチェーンとなって、プロジェクトのリードタイムを引き伸ばす。
プロジェクトを掛け持ちしているのは、なにも優秀なエンジニアだけじゃない。人員数に対し、プロジェクトの並列数が多すぎるのだ。誰もがプロジェクトを掛け持ちしている。掛け持ちするプロジェクトの数が多いほど、出席しなければならない会議体も多くなる。エンジニアはもはやコードを書く時間などほとんど残されていない。これでタスクを遅延させるなと言う方が無茶だ。何とか残業でこなすしかない。
残業で長時間労働が常態化すると、新しい技術を試したり学んだりする時間をエンジニアから奪う。実務の中で伸ばせるスキルもあるが、ソフトウェアエンジニアリングの世界で生き抜くにはそれだけで十分なのだろうか。技術も方法論も日進月歩だ。このままでは個人としても組織としても世界に遅れをとる。その上、プロジェクトチームはプロジェクトが終われば解散する。チームとして積み上げた能力もそこで失われるのだ。唯一の救いは、プロジェクトで得たナレッジをライン組織内で共有していることだけかもしれない。
エンジニアが所属するライン組織は、さながらリソースプールだ。プロジェクトが立ち上がる度にエンジニアを貸し出す。ラインマネージャーは、誰がいつからいつまでどのプロジェクトにアサインされるのかをスケジューリングし、管理する存在でしかない。どこかのプロジェクトで遅延が発生すると、プロジェクトから人員が解放される時期も遅れる。それがリソース計画を狂わせ、他の複数のプロジェクトに影響を及ぼす。マネージャーは、プロジェクト間でのリソース調整に常に追われることが宿命のようだ。
このような中でラインマネージャーはどうやってメンバーを評価するのだろう。メンバーは、日常的な業務をプロジェクト内で遂行している。その活躍ぶりをラインマネージャーが観察する機会は多くない。評価に対するメンバーの納得度は限りなく低くなるだろう。
モノリスチームという技術的負債生成器官
はじめは少人数のチームであっても、マーケットにおけるプロダクトの存在感が高まるにつれ増員を重ねることになる。そこからの道は二手に別れているが、その分岐にさえ気付かず、チームもソフトウェアシステムもモノリス化へと突き進んでしまう。そんなソフトウェアプロダクト開発組織もある。むしろ昔はその方が主流だったように思う。
このようなモノリスチームは、20~30名を優に超える大所帯を抱えた単一チームとしてソフトウェアデリバリ業務にあたる。
モノリスチームが育てたモノリスシステムは巨大過ぎて、我慢ならないぐらいビルドが遅い。こまめに統合していたら時間がいくらあっても足りなくなるから統合の頻度が下がる。継続的インテグレーションにはほど遠い。こんな有りさまだから、いざ統合しようという段階で問題が頻発する。
その上、バッチサイズは常に大きい。そりゃそうだ。チームサイズが大きいのだから、それに比例してバッチサイズも当たり前に大きくなる。そしてそれは、リリースリスクが大きくなることも意味する。リリースする度にトラブルを起こすので、CFR(Change Failure Rate)は酷いあり様だ。
チームにとってリリースは恐怖でしかない。そのストレスから逃れたいから、リリース頻度は下がる一方だ。残念なことにそれがバッチサイズをまた一段と大きくし、リリース時のトラブルは益々頻発することになる。
多発するトラブルを一刻も早く収めるよう、経営リーダーからプレッシャーを受けるのはマネージャーだ。もはやチームに任せてはいられない、自分が何とかせねばとマイクロマネジメントが常態化する。品質を上げたい一心で、マニュアルテストはより重厚になる。あらゆる開発フェーズには長い長いチェックリストが作られていく。それらが正しく実施されたことをチェックする承認フローまで設けられる。プロセスはより厳格で重厚なウォーターフォールになっていく。
かろうじて品質が安定しだしても、悲しいことに経営リーダーは喜ばない。リードタイムが長くなり過ぎたのだ。こんなパフォーマンスでは、ビジネスチャンスを掴めない。競合プロダクトに先を越され、マーケットでの競争力など無いに等しい。
その一方で、数多くのテストケースとチェックリスト項目に埋もれたチームメンバーたちは、自分がまるでマシーンになったように感じはじめる。指示されたことにただ従うだけの存在だ。規律正しいことだけが評価される。達成感も得られず、仕事は楽しくない。心血を注いできたプロダクトの競争力は無くなり、誇りも持てなくなった。そうして一人、また一人と会社を去っていく。優秀な人ほど先に辞めていく。
チームは欠員を補充しながら何とかこの鈍重なプロセスをまわし続けるが、初期からのチームメンバーが去った傷跡は大きい。システムがブラックボックス化してしまうからだ。小さな変更でさえ、その影響範囲の調査に膨大な時間がかかるようになる。詳細設計レベルまで進めないと開発規模を見積もることさえできない。だがそこまでしても、影響範囲の考慮漏れによるトラブルを度々発生させてしまう。
影響範囲を最小限にとどめたいから、消極的な設計が横行するようになる。既存コードや既存データにできる限り影響を及ぼさない設計を選択してしまうのだ。本来であれば既存のメソッドの変更で済むようなケースであっても、もとのメソッドを複製してそちらを変更する。こうしてコードの重複が生み出され続け、保守性は著しく悪化していく。
こんなことが巨大なバッチサイズでリリースの度に繰り返されるのだから、状況は酷くなり続ける。モノリスチームはまるで、技術的負債の生成器官のようだ。このネガティブスパイラルはいずれ、プロダクトを変更不可能な状態にまで追いやるだろう。
かろうじてチームに留まってくれた古参で優秀なエンジニアは、チーム内外から引っ張りだこだ。彼に聞けば安心だ、彼を通さないなら進めちゃだめだ、となる。そうやって属人化が進み、彼がボトルネックとなってリードタイムは更に悪化することになる。
低凝集チームが構成する分散モノリス組織
モノリスチームと対極にあるスモールチームならどうだろうか。7±2名程度のメンバーが固定で所属するチームが複数集まり、ソフトウェアプロダクトをマイクロサービスアーキテクチャやモジュラモノリスで分割統治する。このようなタイプの組織は今や珍しい存在ではないが、必ずしも上手くいくとは限らない。
複数チームと言っても人材には限りがあるから、必要な数だけチームを配置することは現実的に難しい。無理にチーム数を増やすと、一部のメンバーはチームを掛け持ちせざるを得なくなる。チームを掛け持ちするメンバーがいると、チーム間でのリソース管理が必要になる。掛け持ちメンバーによってチーム間が結合されているのだ。この調整によって、それぞれのチームのリードタイムが引き伸ばされてしまう。
一方でソフトウェアプロダクトのコンポーネント間は、依存関係を上手く設計したので結合度は低い状態だ。コンポーネントにはそれぞれオーナーとなるチームを決めており、コンポーネントへの変更はオーナーチームが担当する。どのコンポーネントでも自由に変更できるよう、オーナーを決めないやり方もあるが、そうするとコンポーネントへの変更でチーム間調整が頻発する恐れがある。複数チームで同一コンポーネントを同時期に変更することが起こり得るからだ。
これでチームが独立してコンポーネントを変更し、デプロイできるはずだった。しかし現実はそう甘くない。ひとつのフィーチャ開発で変更対象となるコンポーネントの数は、複数に及ぶことの方が多い。そのオーナーが単一のチームに収まらない。コンポーネントの変更に関してチーム間で調整する必要が頻発したのだ。
これは、各チームに対するコンポーネントオーナ権のパッケージングが適切ではないことによるものだ。チームとしての凝集度が低い、と考えれば分かりやすい。DDD的に表現すれば、コンテキスト境界が適切ではないということだ。
諦めて複数チームで協力して開発を進めることにするが、このやり方はチーム間にタスクの従属関係を生じさせる。一般的に、リードタイムを悪化させる主な原因としてタスクの従属関係が挙げられる。そのタスクの従属関係がチーム間で発生するのだから、リードタイムへの影響はなおさら酷い。あるチームにとっては優先順位の高いフィーチャ開発が、別のチームにとってもそうであるとは限らないからだ。チームはそれぞれにミッションや目標を持つため、チーム間で優先順位を揃えることは容易くない。
何とかスケジュールの調整を終えて開発を進めても、チーム間での開発スケジュールの合流ポイントで問題が起きやすい。従属関係にある先行タスクを担うチームの進捗に遅延が生じれば、後続タスクを担うチームにも遅れが連鎖する。ようやく両チームの成果物を結合すると、今度は両者の仕様の解釈に齟齬があることが発覚する。そしてその手戻りで更に時間を奪われる。
このような調整や齟齬が頻発するから、チーム合同でのミーティングが増えていく。2チーム程度であればそのコストも大したことはないが、コミュニケーションコストはチーム数の自乗のオーダーで大きくなる。チームが多いほどそのコストは組織に重く乗しかかり、ソフトウェアデリバリのパフォーマンスを削り取っていく。
「分散モノリス」という呼び名は、本来、マイクロサービスアーキテクチャのアンチパターンを指すものだ。この名を組織タイプのラベルとして用いたのは、問題構造がよく似ているからだ。チームの凝集度が低いために、チーム間の結合度が高くなる。これが、分散モノリス組織の正体だ。
失敗から学ぶ
多くのマネージャーは、自ら組織を立ち上げるより既存の組織を引き継ぐことの方が多い。そうして担当することになった組織のパフォーマンスを全体最適の中で最大限に高めることがミッションだ。
その遂行には組織のリファクタリングが欠かせないが、いくつもの問題が絡み合って解決の糸口が見いだせないこともある。それこそが、本記事の3つのストーリーのように、組織の構造的な歪みによって生じる問題の可能性が高い。時には大胆に組織をリアーキテクティングすることも必要だ。
最後に、本記事で取り上げた問題のいくつかを列挙する。組織設計の深刻な失敗を回避するヒントや気付きになることを期待して。
- 優れたプロジェクトチームが編成されることは稀だが、時間をかけてチームが成長してもプロジェクト終了と同時にその能力は失われてしまう
- プロジェクトの掛け持ちはクリティカルチェーンとなってリードタイムを悪化させる
- リソースプール化したライン組織では、マネージャーが正しくメンバーを評価することが難しい
- チームメンバーの増加はバッチサイズを大きくする。それがリリースリスクを高め、トラブルを頻発させる。するとチームがリリース頻度を下げはじめ、バッチサイズが更に大きくなるというネガティブスパイラルに陥る
- トラブルの頻発が続くとマイクロマネジメントが始まり、メンバーのやる気を奪い取る
- ソフトウェアプロダクトを分割統治しない体制は、消極的な設計を横行させやすく、技術的負債を生みやすくする
- 複数チームに分けてソフトウェアプロダクトを分割統治する体制であっても、チームの凝集度が低ければチーム間の結合度が高まり、コミュニケーションコストが高くつく。それがリードタイムを押し下げる
関連記事
参考までに。
プロジェクトチーム体制に関連する記事
モノリスチーム体制に関連する記事
分散モノリス組織に関連する記事
その他
マルチバリューストリームというアンチパターン
「保守や運用を考慮した開発」とは言うが、それが意図するところは思うより広い。ソフトウェアエンジニアとしてのその理解は、あくまでもソフトウェアエンジニアリングに閉じたものとなってしまいがちだ。
変更しやすいコードや、システムの安定した稼働は、無論、大切だが、バリューストリーム(value stream)という観点が抜け落ちることがある。そのペナルティとしてチーム間が密結合となってコミュニケーションコストが増大し、テスト容易性とデプロイ容易性を著しく損なう結果を招いたプロジェクトもある。
私が聞いた過去のあるケースでは、複数のアプリケーション間で一部の機能の共通化を進めたことでこのペナルティを支払った。何が問題だったのか。どうすべきだったのだろうか。
そうなったいきさつ
共通化された機能はもともと複数のアプリケーションそれぞれで実装されていた。その機能は、ユーザインタフェースを含め、いずれのアプリケーションもほぼ同じものだった。「ほぼ同じ」なので、わずかな差はある。それがユーザー体験に差を生じさせることが社内で問題視され、互いにユーザインタフェースを揃えることが急務とされていた。
問題視されたのはユーザー体験の差だけではない。ほぼ同じ機能の開発・改善を続けるために、それぞれでエンジニアが稼働するという重複も避けたかった。エンジニアの人数は限られている。競争が苛烈なマーケットで勝ち抜くには、注力すべき領域にエンジニアリングパワーを集中させなければならない。それを削ぐようなムダは少しでも排除する。それが、経営リーダーの意志だった。
こういった背景から方針として打ち出されたのが共通化だった。件の機能を共有コンポーネントとして切り出して各アプリケーションに組み込む、というものだ。
共通化という方式は、実行可能で現実的な判断だった。アプリケーションは、それぞれが異なるビジネス向けに、各々専任のチームによって開発が続けられているが、ウェブアプリケーションという点で共通している。同じ会社の中なので、そこで採用されている技術要素も大差はない。また、各アプリケーションチームがそれぞれで開発していたことからも分かるように、技術的な専門性を要する類のものでもない。
こうして、経営リーダーから号令が発せられ、共通化はビジネス、チームを横断して取り組むプロジェクトとなった。
そしてマルチバリューストリームが発生した
完成した共有コンポーネントによって、ユーザインタフェースは統一された。このコンポーネントひとつに変更を加えれば、全てのアプリケーションに反映できる。
一見すると大成功したかに見えるプロジェクトではあるが、新たに大きな問題を抱えることとなった。共有コンポーネントに対して日々発生する追加開発を通し、チームが互いに密結合になったのである。当然、リードタイムは著しく悪化した。
理由は明らかだった。共有コンポーネントチームが、アプリケーションごとに流れるバリューストリームそれぞれの対応に追われることとなったのだ。「マルチバリューストリーム」とでも言えば良いだろうか。
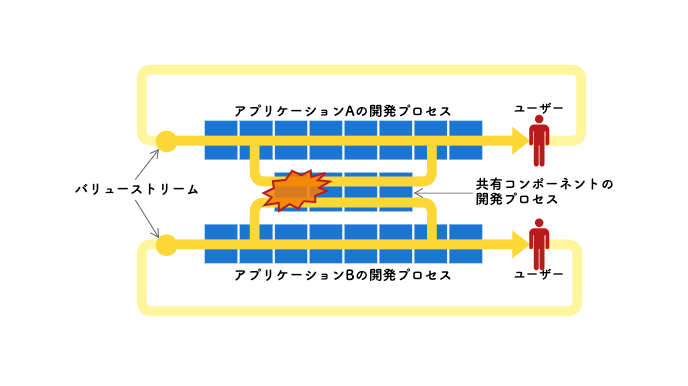
アプリケーションチームは、いわゆるストリームアラインドチーム(stream-aligned team)に位置づけされる存在だ。アプリケーションに対するユーザーのニーズや利用目的は、アプリケーションごとに異なる。それぞれにバリューストリームがあり、それを受けて仮説を立て、アプリケーションに変更を加えていく。
ここで問題になったのは、その過程で共有コンポーネントへの変更の必要性が生じることだ。それは即ち、共有コンポーネントに対する変更理由やタイミングが、アプリケーション側によってもたらされることを意味する。この状況が、閉鎖性共通の原則(CCP, the Common Closure Principle)に反することは明らかだ。コンポーネントを変更する理由は、複数あるべきではない。
共有コンポーネントも、それを利用する各アプリケーションも、それぞれが専任のチームによって開発が続けられている。CCPが守られなかったことで、共有コンポーネントに何か変更を加えようとする度に、これらのチームが集まって、仕様や開発、テスト期間、リリース日などについて話し合い、調整しなければならなくなった。
まるで玉突きのようだった。あるアプリケーションへの変更要求の範囲に、共有コンポーネントに対する機能追加・改善が含まれる。すると、共有コンポーネントを変更する影響が、他のアプリケーションにも波及していく。影響は限定的とは言え、チームが互いに密結合になり、共有コンポーネントの存在がビジネスの足かせになっていった。
更に根深い問題は、この状況にあっても、チームが互いに密結合にあることに気付くものがほぼいなかったことだ。むしろ、チーム間の連携をより強くすべきだと、コミュニケーションの回数・時間を増やし出したぐらいだ。共有コンポーネントの変更による影響で、仕様に齟齬の生じたアプリケーションが障害を起こすことが度々発生したからだ。
こうして各所でチーム間のコミュニケーションパスが増えていき、共有や調整を目的とするミーティングが頻繁に開かれ、コミュニケーションコストが組織の処理能力を減衰させる事態に陥っていった。
なにが起こったのだろうか
共通化という判断は、間違いだったのだろうか。アーキテクチャの視点で見てみると、依存方向は、各アプリケーションから共有コンポーネントへの一方向だ。共有コンポーネントに対してアプリケーションが従属している。この関係においては、共有コンポーネントに対する変更が外部要因となって、従属アプリケーションを変更することはあり得る。
それだけに、責務を負うこととなった共有コンポーネントに対する変更は慎重にならざるを得ないのであるが、従属アプリケーションに対するバリューストリームが、共有コンポーネントを頻繁に変更するモチベーションになっている。つまり変更理由という視点では、アーキテクチャとは関係性が逆転し、各アプリケーションに対して共有コンポーネントが従属しているということになる。アーキテクチャだけでは読み取れない相互依存関係が形成されているようだ。
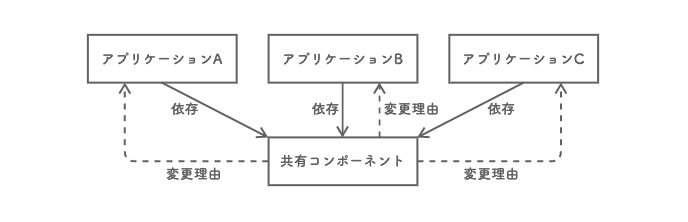
共有コンポーネントチームから見れば、アプリケーションチームは直接のユーザーだ。アプリケーションチームへの提供価値の拡大は、共有コンポーネントの変更理由となるため、この依存関係は正しく見えなくもない。
しかし本ケースでは、共有コンポーネントチームに対し、各アプリケーションチームからプッシュ型でダイレクトに変更要求が押し寄せるようになっている。それがマルチバリューストリームの正体だ。共有コンポーネントチームは、そうやって多方面から流れ込んでくる多くの変更要求の間で生じるコンフリクトやリリースタイミングの調整に追われ続けていた。
社外サービスやOSSライブラリに対して自社アプリケーションを依存させる場合は、こうならない。自社アプリケーションに対するバリューストリームが、社外サービスやOSSライブラリに流れ込まないからだ。会社の内と外という境界に立ちはだかる高い壁が流れをせき止める。
社内開発する共有コンポーネントにも、組織やチームの内と外という壁はあるが、その高さは社外とのそれに比べてあまりに低い。強引に流れを止めようとしても、社内のコンセンサスを得ることは困難だろう。不特定多数を利用者とするOSSや社外サービスと違い、特定少数を相手にするという点も、社内事情の影響を受けやすい理由だと考えられる。
内外を隔てる壁に頼らず、アーキテクチャをより明確・厳密に分離する必要があるのではないか。それが、共有コンポーネントに流れるマルチバリューストリームを分離し、単一のバリューストリームによる独立したプル型のソフトウェアデリバリを実現する道に繋がるのではないだろうか。
どうやって抜け出そうか
まずは問題の整理が必要だ。共有コンポーネントが範囲とするコンテキスト(bounded context)と、従属アプリケーションから流れ込むバリューストリームが扱う範囲の関係をベン図で描いてみると見えてくるものがあった。
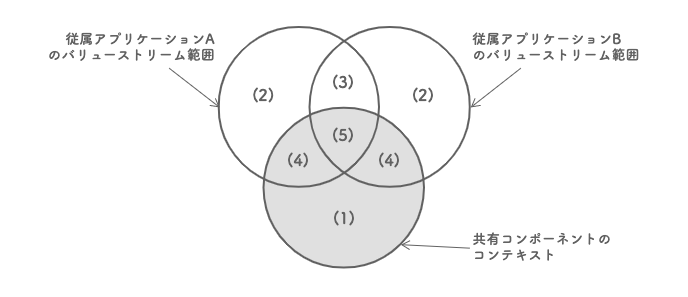
共有コンポーネントのコンテキストの中で、いずれのバリューストリームとも重ならない領域(1)が、共有コンポーネント固有の領域と言える。逆に、バリューストリームが共有コンポーネントのコンテキストと重ならない領域(2, 3)は、それぞれのアプリケーションが扱うべき領域だ。残った2通りの重なり合う領域(4, 5)が、問題の発生源だろう。
まず、共有コンポーネントのコンテキストと、単一のバリューストリームが重なる領域(4)は、それぞれアプリケーション側のコンテキストであるべき可能性が高い。共有コンポーネントがそれを侵犯してしまったために、アプリケーションのバリューストリームが流れ込んでしまっていると考えられる。コンテキストの境界を最初から正確に見極めることなどできないので、これは仕方がない。共有コンポーネントのコンテキストから徐々に切り離していけば良さそうだ。
次に、共有コンポーネントのコンテキストと、複数のバリューストリームが重なる領域(5)は、どう考えるべきだろうか。ここは、共有コンポーネントに対する要求がコンフリクトしやすい箇所とも言える。アプリケーションごとにその使われ方、つまりユースケースやユーザーストーリーが異なるからだ。共有コンポーネントチームがその仲裁に入っているために、いつまで経ってもチーム間が密接に協力し合うコラボレーションモードのインタラクションが続いているのだろう。従属アプリケーションの数がさらに増えれば、コミュニケーションコストが増大することは目に見えている。これはまずい。
要求のコンフリクトが発生する箇所は、それぞれの要求に対する柔軟性が必要な箇所であるとも言える。設定によるカスタマイズ性や、イベントのハンドリング手段、プラグイン機構などを提供すれば、柔軟性を持たせることができる。こういった仕組みを提供することは、チーム間をX-as-a-Serviceモードのインタラクションに移行させ、コミュニケーションコストを下げることにもつながる。
いや、要求のコンフリクトが発生しないこともあり得る。むしろその方が多いのかもしれない。しかしこれを共有コンポーネントチームが一手に引き受けて開発する方式は、ボトルネックになりやすい。
それならば、要求を持つ従属アプリケーションチームが、共有コンポーネントに変更を加えても良いのではないか。コントリビューターとして実装し、コミッターたる共有コンポーネントチームにプルリクを送るという、OSS開発のようなチーム間インタラクションが実現できれば、負荷を分散できる。コントリビューター/コミッターモードでのインタラクションとでも言えば良いだろうか。
もちろん、要求はイシュー管理し、仕様や設計方針は、イシューやプルリクに対するコメントで議論する。共有コンポーネントに関するドキュメントを整備し、テストもデプロイも自動化しておくことが必須になるだろう。
マルチバリューストリームから解放されるために共有コンポーネントチームがやるべきことが見えてきた。
- 共有コンポーネント独自のコンテキスト領域(1)の開発を進めていく
- 共有コンポーネントのコンテキストと、単一のバリューストリームが重なる領域(4)を切り離していく
- 共有コンポーネントのコンテキストと、複数のバリューストリームが重なる領域(5)を次のいずれかで対応する
- 要求のコンフリクトが発生する箇所は、カスタマイズ可能にする
- 要求のコンフリクトが発生しない箇所は、コミッターとして、アプリケーションチームからのプルリクを受けつける
これらの対応を進めるにあたり、アプリケーションチームも対となる対応が求められる。共有コンポーネントから切り離されたコンテキストをアプリケーションに組み込むことや、共有コンポーネントのカスタマイズを進めることなどだ。共有コンポーネントはバージョニングされているので、これらの対応の多くは、共有コンポーネントチームとアプリケーションチームの間で非同期に進められる。
そうは言っても、共有コンポーネントと従属アプリケーションの境界にこれだけの変更を加えるとなると、意図しないトラブルが発生し得る。共有コンポーネントチームはそれを不安に感じ、コンポーネントの変更にためらいを感じるかもしれない。
その不安を軽減するために、アプリケーションチームがテストコードを共有コンポーネントチームに提供しておくと良いだろう。共有コンポーネントに対する担当アプリケーションの要件を、テストコードに書いて引き渡し、共有コンポーネントのビルドパイプライン内でテストが実行されるようにしておく。そうすれば、トラブルを未然に防ぐことができる。マイクロサービスアーキテクチャで言うところのconsumer-driven contrat testingだ。
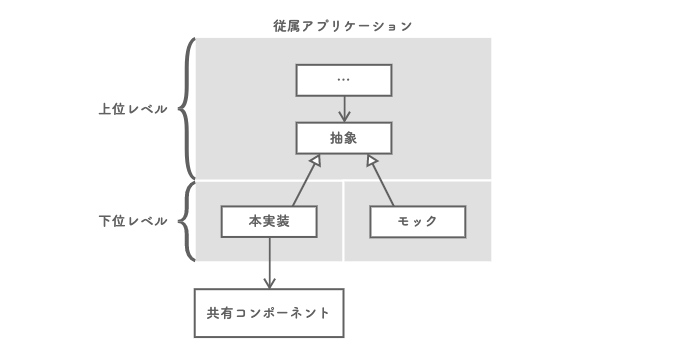
アプリケーションチームには他にもやるべきことがある。共有コンポーネントの変更に対する担当アプリケーション側での変更コストを最小限にとどめることだ。依存先の変更に影響を受けること自体は仕方のないことだが、それがアプリケーションの広範囲にわたるならアーキテクチャに問題がある。影響範囲を特定することが困難になり、修正箇所に抜け漏れが発生しかねない。
この問題は、依存性逆転の原則(DIP, Dependency Inversion Principle)に従うことで軽減できる。「抽象に依存せよ」というやつだ。それぞれのアプリケーション側で、自身が必要とする機能を抽象(インタフェース)として定義し、その詳細(実装)の中で共有コンポーネントに依存させる。こうすることで、アプリケーションの下位レベルが依存する共有コンポーネントの仕様が、上位レベルのコードを汚染することを防ぐ。共有コンポーネントに対する変更は、この詳細の中で制御可能になる。また、抽象があればテストダブルを導入できる。テストにかかるコストも軽減できるだろう。
結論は無い
やるべきことは見えたが、これはあくまでも机上の論だ。マルチバリューストリームで苦労していた他社事例を題材に(多少、肉付けしたが)、どう対処できるかを本エントリを書きながら考えてみたものだ。この事例がその後、現実世界でどうなったのかは聞いていない。
ここに書いたことを実際に実行しようとすると、より難解な問題が多くたちはだかると思う。現実問題として、そもそもこれらを進めていく間も、マルチバリューストリームは流れ続ける。共有コンポーネントチームがその対応に追われていては、状況はいつまで経っても変わらない。崩すべきはまずここからだろう。やり方はいくつか考えられるが、これ以上は論を重ねても実行性がなくなりそうだ。考えるのは、この辺りでやめておこう。
バッチサイズ削減はソフトウェアデリバリに何をもたらすか
「処理能力向上」と「バッチサイズ削減」。ソフトウェアデリバリのリードタイムを短縮したい組織の多くは前者、すなわちチームの処理能力向上に注力する。それが、ソフトウェアエンジニアリングに携わる我々が長年常識としてきたやり方だ。バッチサイズ削減について考えることなどなかった。むしろ、バッチサイズを大きくした方が効率的とさえ考えられてきた。
チームの処理能力向上はもちろん重大な関心事であるが、その実現難易度は高い。時間やコストを要する。それに比べ、バッチサイズ削減は、関係者の合意さえ得られればすぐにでも実現できる。そうであるにも関わらず、バッチサイズ削減という選択肢が軽視されるのは、バッチサイズが及ぼす影響の可視性が著しく低いためではないか。
ドナルド・ライナーセン(Donald G. Reinertsen)は、バッチサイズ削減が、リードタイム短縮やフローにおける変動低減といった効果をもたらすことを挙げている。
- プロセス / フロー / フローユニット
- WIP数 ≠ バッチサイズ
- WIP数の増加によるフロー効率とリードタイムの悪化
- バッチ出発によるWIP数の増加
- バッチ到着による高稼働率の常態化とWIP数の増加
- 変動性と稼働率がリードタイムに与える影響
- バッチ処理によるマルチタスクとオーバーヘッド
- 処理能力向上とバッチサイズ削減
プロセス / フロー / フローユニット
バッチサイズへの理解を深めていく前に、「プロセス」とは何であるかを定義しなければならない。
ソフトウェアデリバリのプロセスは凡そ、実装/コードレビュー/ビルド/テスト/デプロイといった、順序付けられたいくつかのステージが連なるパイプラインとして構成されている。プロダクトバックログから取り出されたアイテムは、それを構成するいくつかのアイテムに細分化された上で、それぞれがこのパイプラインのステージを順に進んでいく。このような、アイテム移動の様を「フロー(flow)」と呼び、移動していく個々のアイテムを「フローユニット(flow unit)」と呼ぶ。

「プロセス」の概念で重要なのは、どこからどこまでをプロセスとするか、観察者がその範囲(システム境界)を任意に定義できる点にある。デリバリパイプライン全体をひとつのプロセスとすることはもちろん、ステージひとつをプロセスとして扱うこともできるし、連続する複数のステージをひと括りでプロセスとして観察することもできる。
プロセスの範囲によっては、フローユニットの粒度にも選択肢がある。デリバリパイプライン全体をプロセスとして観察するなら、トピックブランチに切り出して実装するレベルのアイテムをフローユニットとしても良いし、プロダクトバックログアイテム(ストーリーなど)をフローユニットとしても良い。
WIP数 ≠ バッチサイズ
プロセスにはイベントがある。プロセスへのフローユニットの「到着」と、プロセス内で処理を終えたフローユニットの「出発」だ。到着から出発までの期間にあるフローユニットや、そのフローユニットに対する作業がいわゆる「WIP(Work In Process, Work In Progress, 仕掛り作業)」と呼ばれるものだ。「DIP, Design In Process」と呼ばれることもある。

コードレビュープロセスであれば、プルリクとして投げられたトピックブランチ上の変更(changes)が、フローユニットでありWIPということになる(WIPは仕掛りの「作業(work)」なのだから、正しくは、変更に対する「コードレビュー」作業をWIPと言った方が良いのかもしれない)。
誤解しそうになるが、WIPの数はバッチサイズじゃない。WIP数は単に、ある時点におけるプロセス内のフローユニットの数を示しているに過ぎない。「バッチ」とは、フローユニットのコレクションのことではあるが、むしろ、プロセスに対してひとまとまりで到着したり、出発する単位だと捉えた方が理解しやすい。そのコレクションに含まれるフローユニットの数こそが、本稿の主役である「バッチサイズ」だ。
下図は、バッチによるプロセスからの出発の様子をCFD(Cumulative Flow Diagram, 累積フローダイアグラム)で描いたものだ。

CFDは、時系列でのフローユニットの増加を累積で描いた面グラフで、イシュー管理ツールに付属するレポート機能などで馴染みがあるのではないだろうか。ここでは到着したフローユニットの数をグリーン、出発したフローユニットの数をブルーで表現している。
グリーンとブルーに挟まれた垂直方向の長さは、その時点でのWIP数を示している。それが時間の経過とともに徐々に大きくなっていき、バッチが出発したタイミングで一気に小さくなる。そしてまた徐々に大きくなっていく様子が読み取れる。
WIP数の増加によるフロー効率とリードタイムの悪化
プロセス内のフローの効率性を考える上で、プロセスリードタイムは重要な指標だ(以降は単に「リードタイム」と呼ぶ)。リードタイムとは、ひとつあたりのフローユニットがプロセスに到着してから次へ出発するまでの時間で、WIP時間とも言える。

ここに、処理能力(processing rate, service rate)が1時間あたり平均1/3個のプロセスがある。プロセスが空の状態であれば、フローユニットが1個だけ到着すると、出発するまでのリードタイムが3時間であるこということだ。この期間、WIP数が1個であることに注意したい。

同じプロセスにおいて平均3個のWIPがあるなら、平均リードタイムはどうなるか。

9時間となり、3倍にのびる。リトルの法則からも明らなように、平均リードタイムは平均WIP数に比例するからだ。
平均リードタイム = 平均WIP数 / 平均処理能力

WIP数が3個の時のリードタイムである9時間のうち、付加価値時間(value-added time, service time)はその約33%の3時間だけだ。残りの約67%にあたる6時間は、単なる待ち時間(wait time, queue time)にあてられている。つまり、リードタイムに対する付加価値時間の割合が高いほど、フローの効率性が高いと言うことだ。このような、リードタイムに占める付加価値時間の割合を「フロー効率(flow efficiency)」と言う。
フロー効率(%) = 付加価値時間 / リードタイム
リードタイムとフロー効率に影響を与えるWIP数の変化は、いったい何によって生じているのだろうか。その代表的な要因が、バッチサイズなのだ。
余談ではあるが、プロセスリードタイムは「サイクルタイム(cycle time)」と呼ばれることが多いようだ。しかし、文献によっては、「スループットタイム(throughput time)」と呼ばれ、サイクルタイムが別の意味で使われることもある。このため、本稿では「プロセスリードタイム」あるいは単に「リードタイム」と呼ぶことにした。
バッチ出発によるWIP数の増加
プロセスを出発するフローユニットのバッチ化がリードタイムに及ぼす影響をみるために、バッチサイズの異なる2つのケースを考えてみる。それをCFDとして下図に描いた。書籍『The Principles of Product Development Flow: Second Generation Lean Product Development』の例を参考にしている。

先ほども述べた通り、グリーンとブルーに挟まれた垂直方向の長さは、時系列でのWIP数の変動を表しているのであるから、その合計であるグリーン領域の面積が大きいほど、平均WIP数が大きい。その面積はバッチサイズに比例するので、平均WIP数は、左のCFDの方が大きい。
リトルの法則にある通り、平均リードタイムは平均WIP数に比例する。これらのことから、バッチサイズが大きいほどリードタイムが大きくなってしまうことがわかる。
バッチ到着による高稼働率の常態化とWIP数の増加
大きなバッチとしてフローユニットのかたまりがプロセスに押し寄せれば、WIP数が一気に跳ね上がる。リードタイムが悪化するのは想像に容易いが、プロセスへの影響はそれだけではすまない。
到着のバッチサイズが大きくなる理由はいくつも考えられる。その主要なもののひとつに、稼働率(utilization)を上げようとする意図はないだろうか。それが、高い稼働率を常態化させる。しかし、高稼働率の常態化は、リードタイムの指数関数的な悪化を招いてしまう。
まず、「稼働率」とは、時間あたりに到着するフローユニットの数である「到着率」を、時間あたりに処理できるフローユニットの数である「処理能力」で割った値を言う。
稼働率(%) = 到着率 / 処理能力
例えば、フローユニットがプロセスに到着する間隔が5時間に1個であれば、到着率は1時間あたり0.20個となる。処理能力は、フロー効率が100%である場合のリードタイムが4時間であるとすると、1時間あたり0.25個となる。この時の稼働率は、80%ということになる。
稼働率が100%未満である時の、稼働率とWIP数との関係は、次のグラフのようになる。稼働率が100%に近づくほど、WIP数が大きく跳ね上がる様子がわかる。

リードタイムはWIP数に比例するため、高稼働率にあるプロセスはリードタイムが長い。それは、フロー効率が低い状態でもある。このことから、稼働率とフロー効率の両方を同時に上げることが困難であることが理解できる。このような、フロー効率と稼働率(リソース効率)の関係性を、二クラス・モーディグ(Niklas Modig)とパール・オールストローム(Par Ahlstrom)は、「効率性のパラドックス(efficiency paradox)」と呼んだ。
モーディグらも言うように、効率性のパラドックスは、もう一つの要素である変動性によってより深みにはまる。
変動性と稼働率がリードタイムに与える影響
稼働率とリードタイムの関係は、プロセスが抱える「変動性(variability)」に影響を受ける。「ばらつき」と言った方がイメージしやすいだろうか。その要因は、「リソース」「フローユニット」「外部要因」の3つに分けることができる。
リソースであれば、プロセスを稼働させているチームメンバーの体調やモチベーションによる影響もあり得るし、ビルド環境が壊れることもあるかもしれない。フローユニットの変動として真っ先に思い浮かぶのは、個々のストーリーや機能の開発規模のばらつきだろう。外部要因であれば、割り込みも含め、フローユニットの到着のばらつきが考えられる。
このような変動がまったく無いプロセスはあり得ないが、プロセスによって高変動か低変動かの差はある。次の図は、高変動にあるプロセスと、低変動にあるプロセスに関する稼働率とリードタイムの関係を描いたグラフだ。

高変動にあるプロセスの方が、低変動にあるプロセスより、稼働率がリードタイムに与える影響が大きくなることがわかる。
バッチ処理によるマルチタスクとオーバーヘッド
フローユニット到着のバッチ化は、プロセス内での処理をマルチタスキングに導く。今や誰もが知るように、タスク切り替えによるスイッチングコストは、リードタイムに影響する。
ジェラルド・ワインバーグ(Gerald M. Weinberg)によると、タスクの並列数が2になると、スイッチングコストによって稼働時間の20%をロスし、並列数が3だと40%をロスするという。これも変動と言えるだろう。

処理能力向上とバッチサイズ削減
以上のように、リードタイムは、付加価値時間だけで占められた時間ではない。待ち時間やマルチタスクでのスイッチングコストといった、"非"付加価値時間が多分に含まれている。バッチサイズ削減を通したWIP数のコントロールは、非付加価値時間を削減し、フロー効率を高めようとするアプローチなのだ。
では処理能力向上はと言うと、価値をより短時間で付加する能力を得ようとすることであり、付加価値時間の圧縮を目指すアプローチだと言える。本稿冒頭に書いた「処理能力向上だけでなく、バッチサイズ削減にも目を向けなくて良いのか」という問いは、言い換えれば、「付加価値時間圧縮だけでなく、非付加価値時間削減に目を向けなくて良いのか」という問いでもある。
デヴィッド・アンダーソン(David J. Anderson)によれば、ソフトウェアデリバリのパイプライン全体のフロー効率は概ね1%から25%の範囲に入るようだ。これはつまり、付加価値時間の圧縮効果はリードタイム全体の1%から25%程度であり、非付加価値時間の削減効果は75%から99%ものポテンシャルを秘めているということでもある。バッチサイズ削減に取り組まない手はないだろう。
バッチサイズ削減を突き詰めようとすると、トピックブランチを統合ブランチにマージして以降のフローが自動化され、かつ疎結合であることが鍵となる。ここのコストが高いと、バッチサイズを大きくしようとする力が働く。目指す究極は、継続的デプロイ(continuous deployment)による一個流しだ。そのためにはニコール・フォースグレン(Nicole Forsgren)らが言うように、「テスト、デプロイの自動化」とあわせて「デプロイとテストの容易性」に注力すべきであることは言うまでもない。
技術的負債は開発者体験を悪化させる
ソフトウェアエンジニアにとって、技術的負債が増え続けるソフトウェアプロダクト開発現場に身を置くことがどれほど苦痛なことであるか。エンジニアリング組織のマネジメントを長年担ってきて、それは強く感じるところだ。
中途採用の選考プロセスに面接官として参加し、これまで数多くの退職理由を見聞きしてきた。その中で、レガシーシステムをリファクタリング・リアーキテクティング・リライトできないことへの不満を理由として挙げるエンジニアは多かったように思う。裏を返せば、自社のソフトウェアプロダクトが技術的負債にまみれたまま放置されているなら、優秀な人材が他社に流出するリスクがあると認識すべきだ。
本稿では、技術的負債と開発者体験の関係について紐解くとともに、それに対してソフトウェアエンジニアリング組織を預かるマネージャーが取るべき行動について考えてみたい。
※これは、Engineering Manager Advent Calendar 2021 の21日目の記事です。
- バックログアイテムの分類にみる不可視領域と開発者体験の関係
- Failure Demand という利子の支払いに追われるエンジニアの疲弊
- 開発者体験の悪化が組織を単なる集団に変えていく
- 技術的負債が増え続ける背景
- コード品質にもSLOとエラーバジェットを
- 負債ベースラインと負債上限によるポリシー策定
- 高い保守性というコーディング指針の言語化
- 継続的インスペクションによるコードレビュー負荷の軽減と手戻りの防止
- 技術的負債の原因の多くはアーキテクチャ選定の失敗
- 最後に - エンジニアが組織やプロダクトに誇りを持つために
- 追記:YouTube Liveでの登壇時のアーカイブ
バックログアイテムの分類にみる不可視領域と開発者体験の関係
下の図は、バックログに含まれるアイテムをカテゴライズし、4色に色分けしたものだ。フィリップ・クルーシュテン(Philippe Kruchten)によって2009年頃に考案され、"What Colo(u)r is Your Backlog?" というタイトルで発表された。ここでは2013年に彼のブログ記事で紹介されたバージョンに基づいている。技術的負債(technical debt)を返済するためのアイテムは、右下の黒いエリアにカテゴライズされている。

四象限の左側にカテゴライズされたバックログアイテムは、ソフトウェアプロダクトの「振る舞い(behavior)」を変える・正すものだ。振る舞いは目に見える(visible)。「振る舞いを変える/正す」目的は、「ユーザー体験(UX, User eXperience)」を向上・改善することだろう。
対となる右側にカテゴライズされたバックログアイテムは、ソフトウェアプロダクトの「構造(structure)」を変える・正すものだ。構造は目に見えない(invisible)。「構造を変える/正す」目的は、振る舞いの「変更容易性(modifiability)」を向上・改善することだろう。
「振る舞いを変える/正す」のはエンジニアの役割なのだから、ソフトウェアプロダクトの変更容易性の良し悪しは、エンジニアの体験に影響を与える。「構造を変える/正す」意思決定が適切になされないと、「開発者体験(DX, Developer eXperience)」が悪化することが想像できる。

フィリップ・クルーシュテンの同ブログ記事にも書かれているように、右上の黄色いエリアである「アーキテクチャ(architectural, structural features)」にカテゴライズされるアイテムに手を付けない選択は、右下の黒いエリアである「技術的負債」にカテゴライズされるアイテムの増加につながってしまう点も留意すべきだろう。
Failure Demand という利子の支払いに追われるエンジニアの疲弊
変更容易性の悪化が、ソフトウェアデリバリのリードタイム(lead time for changes)を悪化させることは言うまでもない。マーティン・ファウラー(Martin Fowler)によれば、コード品質を高く保つコストを削ることで生産性を上げる試みが通用する期間、いわゆる "design payoff line" に到達するまでの時間は、せいぜい数週間以内だと言う。
それに加え、複雑化しすぎたコードを変更することは、多くのバグを生み出しやすい。それがリリース後の障害となり、変更失敗率(change failure rate)を押し上げる。こうしてエンジニアは度重なる障害対応に追われ、精神をすり減らし、疲弊していく。
このような、本来やるべきことをやらなかったために後から強いられる労力のことを "failure demand" と言う。技術的負債のメタファーで言えば、「利子を支払う」といったところだろう。この利子の支払いは、エンジニアが新たな価値を生み出す "value demand" のための時間を奪い、開発現場は益々混乱していく。書籍『LeanとDevOpsの科学』によれば、ローパフォーマーに分類される組織は、ハイパフォーマーに対して「予定外の作業や修正作業」にかかる時間比率が6ポイントも高い。

経営者やビジネスマネージャーからすれば、少しの振る舞いの変更に、なぜこれほどまでに時間がかかるのか理解できない。その上、障害まで頻発する。こんなことが続けば彼らは、エンジニアに対して不満と不審感を抱くようになる。その感情はエンジニアにも伝わる。エンジニアはきっと、やり切れない気持ちになるだろう。
開発者体験の悪化が組織を単なる集団に変えていく
2012年に行われたGallupの調査では、従業員エンゲージメント(employee engagement)の高さで上位4分の1に入る企業は、下位4分の1の企業に対し、顧客評価で10%, 生産性で21%, 収益性で22%上回った。また、欠勤は37%, 離職率は25%から60%、品質上の欠陥は41%下回った。

従業員体験(EX, Employee eXperience)は、従業員エンゲージメントに影響すると言われている。開発者体験も同様だろう。
先述したように、「構造を変える/正す」ことを軽視することは、リードタイムや変更失敗率といったソフトウェアデリバリのパフォーマンスを悪化させる。しかし、従業員エンゲージメントに関する調査結果からもわかるように、開発者体験が悪ければ、ソフト面からビジネス成果や組織の持続可能性を押し下げることになる。
これは、チェスター・バーナード(Chester I. Barnard)の言う組織の3要素のうちのひとつである「協働意思(willingness to serve)」が失われるからだろう。組織が組織たり得ず、単なる人の集まり、つまりは「集団」の状態に陥ってしまうのだ。
技術的負債が増え続ける背景
このような問題を生み出す背景のひとつには、「振る舞いを変える/正す」ためのバックログアイテムばかりが優先順位の上位に並んでいるという状況がある。「構造を変える/正す」ためのバックログアイテムに着手される日は、なかなかやってこない。
優先順位の決定権者にとっては、ユーザー体験を高め、プロダクトのユーザー価値を高めることこそが優先課題だ。それが、プロダクトのビジネス価値向上につながる道だからだ。ソフトウェアの「構造を変える/正す」ことに取り組んだところで、少なくとも短期的にはビジネスに良い影響を与えるように感じられない。そんなものは少しでも後回しにして、「振る舞いを変える/正す」ことに集中したい。
エンジニアの不満は主にここに集中しがちであるが、技術的負債が増え続ける主たる理由は本当にこれだけだろうか。
それを知るためには、技術的負債と呼ばれるコードを自分の目で確かめると良い。そうすると、別の根深い問題が潜んでいることに気づく。とんでもなく低い技術レベルで書かれたコードが数多く紛れ込んでいるからだ。
書籍『How Google Works』によれば、Google(Alphabet)社には、「採用の質を犠牲にしてまで埋めるべきポストはない」という不可侵な黄金率があるという。採用において、速さか質かという選択肢が迫られる場面では、必ず質を選ぶことで優秀なエンジニアの獲得にこだわる。
しかし多くの企業では、採用でそこまでの質を追求できないのが実情だろう。世界屈指のテック企業と比べたら、そもそもの応募者数が違う。結果、社内のエンジニアのスキルは玉石混交、優秀なエンジニアもいれば、プログラミング言語仕様やプログラミングパラダイムを十分に理解していないエンジニアも存在することになる。社内にエンジニアが増えていく企業フェーズでは特に、こういったことが起こりやすい。
そんな状況で、均一的に質の高いコードを維持することは難しい。エンジニア育成にも時間がかかる。数少ない優秀なエンジニアだけでこの状況をカバーすることは不可能だ。
つまり、技術的負債が増え続ける主な背景はふたつ。ひとつは、返済する意思のない無計画な借金を積み重ねること。もうひとつは、一度の借り入れ額が大きくなりやすい問題(技術スキルの低さ)を抱えていること。
マーティン・ファウラーは、前者を「意図的(deliverate)」かつ「無謀(reckless)」な負債と呼び、後者を「無自覚(inadvertent)」かつ「無謀(reckless)」な負債と呼んだ。下の四象限の左上と左下がそれにあたる。
コード品質にもSLOとエラーバジェットを
さて、まずは「意図的」かつ「無謀」な技術的負債への対処方法を考える。
いつまで経っても優先順位の上がらない「構造を変える/正す」ためのバックログアイテムに着手することを、関係者から合意を取り付けようとする開発チームの交渉は、なかなか上手くいかないことが多い。そうであればその大役は、マネージャーの責務であると考えるべきだろう。
しかし、その実践はなかなかに骨が折れる仕事だ。関係者との力関係も影響するし、強力で洗練された説得力も必要になる。その上、こういった交渉の必要性は一度だけでなく、度々発生するであろうことを考えると、対応コストが高すぎる。マネージャーが開発プロセス上でのボトルネックになりかねない。どこかに優先順位付けのための良いバランスツールはないのだろうか。
SRE(Site Reliability Engineering)に、「エラーバジェット(error budget)」というものがある。例えば、あるAPIへのリクエストの95%のレスポンスタイムが400ミリ秒以下であることをSLO(Service Level Objective)としていた場合、400ミリ秒を超えるリクエストが5%未満の間はサービスレベルとして許容できる。この許容幅をエラーバジェットと言う。この考え方が、技術的負債についても応用できそうだ。
エラーバジェットの優れている点は、システムの変更を担う開発サイドと、システムの信頼性を担う運用サイドの対立を、両者の力関係ではなく客観的なメトリクスで解決した点だ。エラーバジェットが枯渇するまではシステムを自由に変更できるが、許容値を超えると機能リリースを止め、信頼性回復に注力する。
このSLOやエラーバジェットのようなものを、コード品質にも取り入れたい。コード品質は静的コード解析ツールなどを利用してメトリクス化できる。そのメトリクスを使ってSLOを策定し、バックログの優先順位決定権者と握っておくのだ。そうすれば、「振る舞いを変える/正す」ことによって生じた技術的負債の量がバジェットを超えた時、開発チームは、「構造を変える/正す」ことに着手できるようになる。
なお、既存のソフトウェアプロダクトのコード品質をメトリクス化すると、最初はひどい結果になる。導入初期段階でのSLOは低めに設定し、徐々に理想的なラインに近づけていく運用にすると良いだろう。
さてこれで、我々マネージャーはコストの高い交渉業務から解放された。やるべきことはただ、この説得力の高いバランスツール導入への同意を関係者から取り付けるだけとなった。
負債ベースラインと負債上限によるポリシー策定
書籍『リーン開発の現場』の著者でもあるヘンリック・クニバーグ(Henrik Kniberg)が、技術的負債のマネジメント手法について、「負債ベースライン(debt baseline)」 と 「負債上限(debt ceiling)」による許容範囲を設けることをブログ記事で提案している。技術的負債がこの許容範囲内に入るようマネジメントしようというものだ。負債上限を超えたら全ての機能開発を止めて、クリーンアップに専念する。この手法が、コード品質のSLOやエラーバジェットの導入にちょうど合う。

ベースラインがある理由は、技術的負債の最後のひとつひとつを取り除いてゼロにする労力が大きすぎるからだ。
また、グラフがノコギリ歯状になっている理由は、振る舞いを変更するバックログアイテム、つまり新機能が提供する価値を仮説だと考えているからだ。リリース後の検証結果によってはその機能の提供を中止するかもしれないし、大幅に方向性を変えるかもしれない。それを前提とすると、仮説である間はコード品質を求め過ぎるのも非効率だ。検証によって価値が証明されてからクリーンアップするのが効率的だろう。これをサイクルとして繰り返すことが、ノコギリ歯で表現されている。それでも取りこぼしがあるだろうから、少しずつ技術的負債が増えていくという構図だ。
ちなみにここでは、素早く仮説検証するために生じた、数日から一週間以内の技術的負債を「良い技術的負債(good technical debt)」と呼んでいる。「意図的」かつ「慎重」な負債にカテゴライズされるものだろう。
技術的負債やコード品質のメトリクス化は、先述の通り静的コード解析ツールを利用するのが良いと思うが、そのメトリクスも完全なものとはならない。ヘンリック・クニバーグの同ブログ記事にもあるように、現場エンジニアの意見を取り入れるのも良さそうだ。
高い保守性というコーディング指針の言語化
次に、「無自覚」かつ「無謀」な技術的負債への対処方法を考える。もちろんエンジニアの技術力の底上げも必要であるが、本稿の趣旨とは外れるためここでは触れないこととする。
コード品質に対するSLOやエラーバジェットの導入は、コード品質の可視化と基準を明確にする。しかし、どのようにしてその基準を達成するのかについては明らかにしていない。つまり、どのように「コーディング」すれば、求めるコード品質となるのかが不明瞭だ。
残念ながら、静的コード解析のメトリクスが良いスコアになったからといって、それが必ずしも「コード品質が高い」ことを表しているとは言いきれない。それでなくても数値目標は、自己目的化しやすい。数値を追いかけるだけになってしまっては、目的は達せられない。どういうコードが「品質が高い」と言えるのか、それはどのようにコーディングすれば到達できるのか、開発チームと共同で言語化し、指針を明確にすべきだろう。
技術的負債をクリーンアップする方法と言えば、「リファクタリング(refactoring)」が真っ先に思い浮かぶ。指針を検討する上で、これが糸口となりそうだ。
リファクタリングの目的は、コードの変更容易性の向上・改善に加え、「理解容易性(understandability)」を向上・改善することだ。コードを変更するには、コードを読み、変更対象となる箇所を特定する必要がある。理解容易性が高いコードは、この探索活動の難易度を下げてくれる。
そして、リファクタリングには自動テストが付きものだ。変更後のコードが仕様通り動くことを簡単に確認するためだ。ここで、「テスト容易性(testability)」が向上する。
このように、リファクタリングによって得られる効果、すなわち「品質の高いコード」とは、変更容易性・理解容易性・テスト容易性が高いコードに他ならない。バリー・ベーム(Barry Boehm)らは、これらの品質特性をまとめて、「保守性(maintainability)」と呼んだ。
目指すべき品質の高いコードとは、変更容易性・理解容易性・テスト容易性を兼ね備えた保守性の高いコードであることは分かった。これは、構造を変える・正すためにリファクタリングする時だけではなく、振る舞いを変える・正すためにコードを書く時にも言えることだ。そして同時に、お馴染みの手法や活動の目的も次のように明確になる。
- 変更容易性・理解容易性・テスト容易性の高いコード設計を導く「TDD(Test-Driven Development, テスト駆動開発)」
- テスト容易性を上げる「テスト自動化(test automation)」
- 保守性の高さを観点とした「コードレビュー」、または「ペアプログラミング」「モブプログラミング」
特に、いくつかのチームリーダーやマネージャーにコードレビューの観点についてヒアリングしたところでは、明確な基準が存在していないケースが多かった。それでは一貫したコード品質は得られない。保守性の高いコードとはどういうものであるかをチームで具体化し、それを観点とするレビューが実施できる状態を目指したい。
なお、「どのようにコーディング」コーディング指針やモジュールの依存関係に関するルールなどをテストコードにすることもできる。こちらについては、記事『ArchUnitでアーキテクチャをテストする - mtx2s’s blog』に書いた。
継続的インスペクションによるコードレビュー負荷の軽減と手戻りの防止
ところで、コードレビューには2点ほど問題があると考えている。
ソフトウェアデリバリのリードタイム改善を進めていた時に気付いたのだが、コードレビュー待ちで止まってしまうワークアイテムがそれなりに多い。レビュアーが複数のレビューを抱えていたり、自身もコーディング中のワークアイテムを抱えていたりして忙しいからだ。
ある調査によると、コードレビューの効果を高めたいなら、「一度にレビューするのは400LOC未満」「一時間あたり500LOC以下」「一度に60分以上のレビューをしない」のが良いらしい。それなりに時間がかかる。忙しい身で品質の高いレビューは難しい。これが一つ目の問題だ。
二つ目の問題は、コードレビューがコーディングの最後に行われる点だ。大きな問題が見つかった時の手戻りが痛い。
これらの問題の対策として、ペアプロやモブプロも良いのだが、あわせて「継続的インスペクション(continuous inspection)」の導入も検討したい。せっかく静的コード解析ツールを導入したのなら、それをCIのパイプラインに組み込み、コーディング中、プルリク時、ビルド時に自動で検査すれば良い。そうすることで、レビューによる負荷も軽減されるし、コーディング段階からコード品質を検査することが可能になる。
技術的負債の原因の多くはアーキテクチャ選定の失敗
Software Engineering Institute(SEI)が、大企業3社(39ビジネスユニット)で働くソフトウェアエンジニアとアーキテクトを中心とする1,831名を対象に行った調査によると、技術的負債の原因として回答者に最も多く選択されたのが「アーキテクチャ選定の失敗」だった。
下のグラフは、14の選択肢をプロジェクトにおける負債の量でランク付けするよう求めた結果を、1位、2位、3位のいずれかに選んだ回答者の数で集計したものだ。

アーキテクチャを入れ替えるには、大規模なリファクタリング、いや、おそらく「リアーキテクティング(rearchitecting)」が必要になる。
リアーキテクティングは時間がかかる上に、場合によってはその実施期間中、新機能開発を止めなければならないこともある。プロダクト開発に対してそのような厳しい制約を課すバックログアイテムの着手には、優先順位決定権者も簡単には許可を出せない。
しかしそれは、提案したリアーキテクティング計画の着手時期が早すぎるからだ。ビジネスには四半期や半期、通期ごとに目標がある。優先順位決定権者は、リアーキテクティングの実施が目標達成に影響を及ぼすことを危惧している。
だから、リアーキテクティングの実施を、目標達成に影響を及ぼさない時期にプロットすれば、意外とすんなり受け入れられる。次の目標策定時の計画に含められるからだ。そのためにもリアーキテクティング実施計画は十分に前もって準備を進めておきたい。
もちろん、リアーキテクティングを成功させるためには、十分な技術スキルとドメイン知識を持ったアーキテクトの存在と、その設計思想を適切にコードに変換できる能力がチームに求められることは、言うまでもないだろう。
最後に - エンジニアが組織やプロダクトに誇りを持つために
過去に、私がマネジメントすることになったばかりの組織のエンジニア数名に対して「もし、開発業務として自由な時間があるなら何がしたい?」と聞いたことがある。彼らの答えは概ね、担当する既存プロダクトのリファクタリング・リアーキテクティング・リライトのいずれかだった。これは、冒頭に書いた退職理由と同じだ。彼らは自分たちが作り上げたソフトウェアプロダクトやチームにも誇りを持っていなかった。むしろ否定的だった。
私は、自らが担当するエンジニアリング組織のミッションを、組織としての「プロダクト開発能力の差異化」だと定義している。市場においてプロダクトの優位性を獲得することに高い再現性のある組織を目指していると言えば伝わるだろうか。
その開発能力の源泉となるのは、チームやプロダクトに誇りを持って開発を続ける優秀なエンジニアたちだ。技術的負債の放置は、リードタイムや変更失敗率が悪化するというソフトウェアデリバリ面だけでなく、開発者体験、言い換えれば従業員エンゲージメントを悪化させる。これでは「プロダクト開発能力の差異化」の実現が遠のいてしまう。それだけに、技術的負債のマネジメントは、エンジニアリング組織を預かるマネージャーの重要な責務だと考えている。
追記:YouTube Liveでの登壇時のアーカイブ
本稿公開からちょうど1年後にあたる2022年12月21日に、本テーマをもとにイベント登壇した。タイミー社が主催するTech勉強会「技術的負債の返済から改善する開発者体験 - Techmee vol.5」でのゲスト公演枠で、その時の様子はYouTubeにアーカイブされている。
登壇時の資料はspeakerdeckに置いてある。