チームのマネージャーが、自らの責務をジョブディスクリプションとして明文化することは難しい。職務内容や権限を、断片的にしか書けないかもしれない。もしそうなるなら、実務も断片的になっている可能性がある。
チームマネジメント(組織マネジメント)という活動は、個々のマネージャーの経験や関心によって、断片的になりやすいように感じている。断片的とは、マネジメント活動が、責務の一部の領域に偏ってしまっていたり、問題を検知してはじめてその領域がマネジメント範囲であることを知る、といった様子を指している。
このような状態になる背景は、マネージャーにとって、マネジメントが、日々の実務を通して蓄積された経験に基づく活動になっているからではないか。マネージャーは孤独だ。ひとりでその責務を担う。エンジニアとは違い、チームで協働するわけではない。だから、形式知 として言語化 されず、個人の経験として暗黙知 にとどまる。その内容は個別具体であり、モデル化(抽象化)されず、全体像を構造として捉えきれていない。これでは活動が断片的にならざるを得ない。
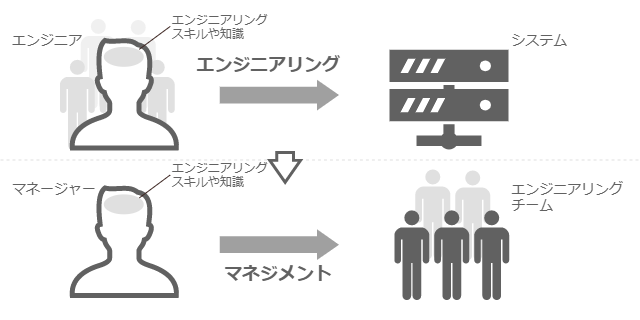
Engineering Management Triangle というものがある。これが作られた背景のひとつも、きっと似た問題意識からだろう 。本ブログも、エンジニアリングとそのマネジメントを対象としているが、少し違ったアプローチでマネジメントを体系化してみようと思う。それは、エンジニアスキルを活用してチームマネジメントを捉えることだ。
エンジニアリング経験を持つマネージャーは多いと思う。そこで得たスキルや知識は、チームマネジメントをひも解くために非常に役立つ。「エンジニアリングとシステム」という関係は、「マネジメントとチーム」という関係によく似ているからだ。
エンジニアリングとマネジメント
本ブログエントリーでは、チームをシステムとして捉え、そのアーキテクチャ ・構造を辿りつつ、その中にマネジメント活動をプロットしていく。これが、多岐にわたるチームマネジメント活動を、マネージャーが思考の中で整理するヒントになれば、と願っている。
なお、ここではエンジニアリングチームのマネジメント(組織マネジメント)のみを扱い、プロジェクトマネジメントやプロダクトマネジメント は含めない。特に、企業組織のツリー構造上で、リーフとなるようなチームを想定している。
サービスの枠組み
共通目的が形成するサービス
ソフトウェアシステムは、何らかの背景や目的があって生み出される。それは企業課題に対するソリューションの場合もあれば、日頃のちょっとした不便を解消するためのツールの場合もある。
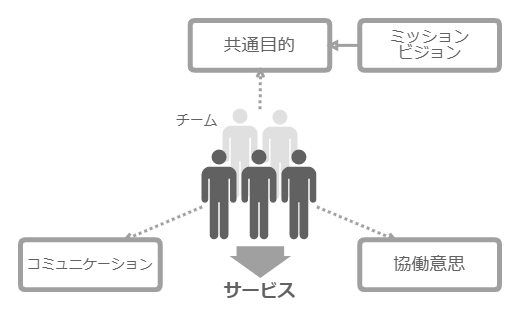
組織も、目的があるから存在する。経営学 者のチェスター・バーナード(Chester I. Barnard) は、組織を「協働のシステム(cooperative system) 」と呼んだ。そして、集団が組織として成立する条件のひとつに、「共通目的(common purpose) 」を挙げている。これは組織の存在意義のことであり、ミッション やビジョン のことだと言える。
An organization comes into being when (1) there are persons able to communicate with each other (2) who are willing to contribute action (3) to accomplish a common purpose. The elements of an organization are therefore (1) communication; (2) willingness to serve; and (3) common purpose. These elements are necessary and sufficient conditions initially, and they are found in all such organizations. - The Functions of the Executive
(組織とは、(1)互いにコミュニケーションできる人々がおり、(2)活動に貢献する意思がそれらの人々にあり、(3)共通目的を達成するためにその活動を行う時に、成立する。組織の要素とはすなわち、(1)コミュニケーション、(2)協働意思、(3)共通目的だ。これらの要素は組織成立にあたり必要十分条件 であり、そのような組織すべてに見られる。 - 『経営の役割』)
チームも組織であり、ミッション・ビジョンを共有(common purpose) し、その遂行・実現に向けて互いに意思疎通(communication) をはかり、協働(willingness to serve) する。この活動を、企業では事業(ビジネス) や業務 と言う。以降は、これらを汎化してサービス と総称する。つまりチームとは、サービスを提供するシステムなのだ。
チームとサービス(事業・業務)
このように、チームがシステムとして機能し、最適なサービスを提供するためには、そこに参加する人々が目的(Why)をしっかりと見据えていなければならない。こういったコンテキストでよく引用される、ドラッガーの石切り工の話 がある。
三人の石切り工の昔話がある。彼らは何をしているのかと聞かれたとき、第一の男は、「これで暮らしを立てているのさ」と答えた。第二の男は、つちで打つ手を休めず、「国中でいちばん上手な石切りの仕事をしているのさ」と答えた。第三の男は、その目を輝かせ夢見心地で空を見あげながら「大寺院をつくっているのさ」と答えた。
チームの目的を理解しているのは第三の男で、第一の男は個人の目的、第二の男は手段について話している。ここでのマネージャーの活動は、第三の男として、チーム全体に目的を浸透させ、皆に同じ方向を見させることだ。そうすれば、チームは状況に応じた正しい判断を下せるようになる。
ジョナサン・ラスムッソン(Jonathan Rasmusson)は著書『アジャイルサムライ−達人開発者への道− 』で、これを「みんなをバスに乗せる(原著では "How to get everyone on the bus") 」と表現し、その方法としてインセプション デッキインセプション デッキを試してみるのも良さそうだ。
サービスのコンテキスト境界と機能
ドメイン駆動設計(Domain-driven design, DDD) ドメイン 領域を、「境界付けられたコンテキスト(bounded context) 」として、特定のモデルを共有する範囲で分割する。理想的には、分割されたひとつのコンテキストごとに、ひとつのアプリケーションを対応付ける。
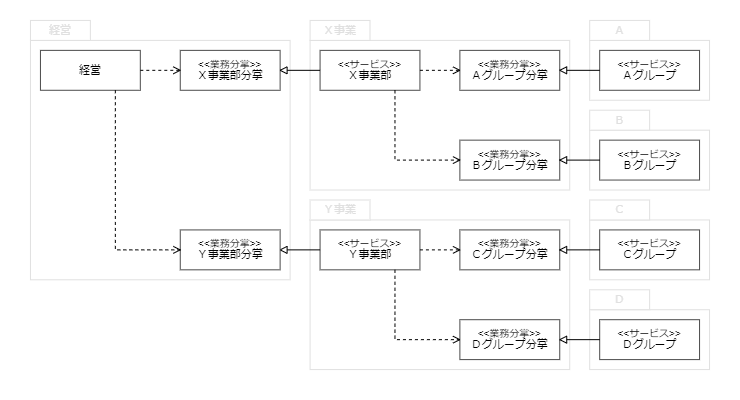
企業でのコンテキスト境界は、組織構造として反映されている。その構成要素たる部門・部署が、チームとして特定の事業や業務、すなわちサービスを担う。これを、文書として記述したものが業務分掌 だ。業務分掌の中では、それぞれのサービス(チーム)の責務として配分された機能 が規程されている。
一般的に、組織構造はツリーを形成している。上位の包括的なサービスを実現するために、下位の部分的なサービスが存在するという構造を持つ。例えば、E コマース事業(上位サービス)には、仕入 れ、カタログ製作、マーケティング 、注文管理、フルフィルメント、カスタマーサービス といった業務(下位サービス)が必要となる。これらが互いに連携することで、事業として成立する。だから、サービスごとの業務分掌は、関係するサービス間で漏れや重複が出ないよう、整合性を取らなければならない。
このことから、自らが担当するサービスの業務分掌を、マネージャーが単独で定義するケースはあまりないだろう。最上位にあたるサービスの業務分掌を、経営者自身や経営企画部門・事業企画部門が定義し、そこからは、上位のサービスを受け持つマネージャーが、直下の組織分割や業務分掌定義を行う、といった運用が多いのではないだろうか。下位のサービスを受け持つマネージャーが、この活動を支援することもあるだろう。
組織構造とサービスの関係
この構造によって、下位レイヤーサービスの実体(実装)は、上位レイヤーが要求するサービスの枠組み、すなわち業務分掌に依存することになる。上位のサービスが、下位のサービスの実装に影響を受けないようデザインされているということだ。これは、業務分掌を抽象(abstraction) とした依存性逆転の原則(dependency inversion principle, DIP ) だとみなせる。
機能を表現する振る舞いの抽象定義
ソフトウェアが持つ機能は、そこに含まれる振る舞い(behavior) の集合によって表現される。そして、外部との境界面の振る舞いをインタフェース(interface) として抽象定義することで、機能のデザインから、実装を分離可能にする。オブジェクト指向 プログラミングなら、抽象型(Java 言語なら interface)として存在する。サービスレベル(REST API や RPC)では、OpenAPI Specification(OAS) Protocol Buffers IDL(Interface Description Language, Interface Definition Language)
業務分掌も抽象ではあるが、その抽象度が高すぎるため、インタフェースとしては使えない。しかし、サービス外部との境界面となるインタフェースがなければ、サービスの実装が分離できなくなる。これでは実装の変更時に、その影響がサービス外部に伝搬してしまう。だからマネージャーは、業務分掌に規程された機能ごとに、外部接点となる振る舞いの集合をインタフェース化して抽象定義する。サービスインタフェースの仕様は、ドキュメントなどにまとめ、サービス利用者に提供する。
サービスの実体
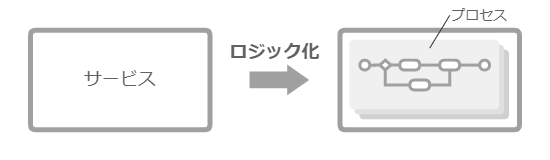
プロセスはサービスのロジック
「プロセスを踏む」という表現がある。目的とする成果や状態に到達するために、あらかじめ定義された手順を進める、そんな意味合いだろうか。プロセスは、フローと言い換えることもできそうだ。すると、プロセスが、UML のアクティビティ図 のようなものだとわかる。つまり、ロジック だ。
ビジネスプロセス や業務プロセス は、サービス(事業・業務)に関するロジックを定義している。「ビジネスプロセス」や「業務プロセス」より「ビジネスロジック 業務ロジック 」の方が、エンジニアにはなじみ深い。サービスは、複数のこういったプロセスで成り立っている。例えばソフトウェア開発業務なら、開発プロセス が主たるプロセスとなる。このような、プロセスの開発・保守は、マネージャーにとって重要な仕事のひとつだ。
サービスに関するプロセスがロジック
プロセスは、一度作り上げたらそれで終わりではない。ビジネス要求の変化に応じ、プロセスに変更を加えることもある。ここで安易なロジックを組んでしまうと、プロセスの保守性 や拡張性 を落とし、新たな変更を加えにくくする。これは技術的負債 リファクタリング
サービス利用者との接点になるようなアクティビティは、あらかじめサービスインタフェースとして規定した仕様に従い、実装する。もし、プロセスの変更によって、サービスインタフェースの仕様を変更することになった場合は、新しい仕様をサービス利用者にアナウンスすることを忘れない。新旧両方のバージョンをしばらく並行稼働させるケースもあるだろう。
日々発生する例外は、例外処理フローとして新たなロジックを組む。こうしてプロセスを洗練させ、継続的にサービス品質を向上させていく。
ソフトウェアフレームワーク は、ソフトウェアを制御する汎用的な機構、あるいは型だ。「汎用的な機構」が既にコードとして書かれた状態で配布されるため、フレームワーク の利用者は、個別具体的なロジックを組むだけで、品質の高いソフトウェアを短時間で作り上げることができる。
プロセスにも、プロセスフレームワーク (プロセスモデル ) というものがある。開発プロセス なら、スクラム やウォーターフォール がそうだ。これ自体ではプロセスとして機能しないが、このフレームワーク に沿って、必要なロジックを組み込むことで、品質の高いプロセスを作り上げることができる。
マネージャーは、こういったプロセスフレームワーク をぜひとも活用すべきだろう。ソフトウェア開発と同じで、汎用的なものを自社開発して利用することは、特別な理由がない限り避けたい。限られた時間を、汎用的なものより、個別具体的なロジックの開発にあてたい。それに、様々なプロセスで利用され、鍛え上げられたフレームワーク は柔軟性も高い。プロセスを運用していく中で、後から加えていく変更にも柔軟に対応できる。『スクラムガイド 』を見るとわかるように、フレームワーク 自体が日々、メンテナンスされ、進化し続けているものもある。
フレームワーク の仕様や思想を深く理解しなければ使いこなせないという点は、ソフトウェアフレームワーク もプロセスフレームワーク も同じだ。マネージャーは、チームアーキテクト として、プロセスフレームワーク の選定や、その仕様・思想の理解を進め、メンバーにその内容を浸透させることを怠らない。
PMBOK フレームワーク ではないが、「5 個のプロセス群 × 10 個の知識エリア」のマトリクスでプロセスが整理されている。各プロセスにはインプット/アウトプットが定義されており、プロセス設計のガイドとして活用しやすい。
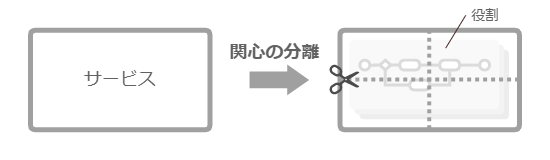
ソフトウェアコンポーネント は、ソフトウェアを関心の分離(separation of concerns、SoC) によって、任意の粒度に分割したものだ。関心とは着眼点のようなもの。これが、コンポーネント 固有の責務(responsibility) を決定づけ、コンポーネント が提供しなければならない振る舞いを明らかにする。
アクティビティ図では、アクティビティパーティション を使い、アクティビティをグルーピングできる。このグルーピングという行為は、関心の分離だ。そこに紐づく責務としての振る舞いを具体化したものがアクティビティだ。そして、ビジネスプロセス・業務プロセスでは、チームメンバーが担う役割 を主たる関心事として、その範囲をパーティション で表現することが多い(パーティション は、サービス利用者や情報システム等としても使う)。言い換えれば役割とは、プロセス開発を通じ、サービスを関心で分割したサービスコ ンポーネント なのだ。
サービスを役割で分割
スクラム では役割を、プロダクトオーナー、開発チーム(メンバー)、スクラム マスターの 3 つに分離している。その中で、スクラム マスターの責務は、次のように定義されている 。
スクラム マスターは、スクラム ガイドで定義されたスクラム の促進と支援に責任を持つ。スクラム マスターは、スクラム の理論・プラク ティス・ルール・価値基準を全員に理解してもらえるように支援することで、その責任を果たす。
スクラム ガイドにはもう少し詳細な責務定義がなされている。プロセス開発では、このような役割毎の責務を踏まえ、その具体であるアクティビティを定義する。
役割の凝集度と再利用性
ところで責務は、「実行責務 」と「情報把握責務 」に分類できる。実行責務は、「振る舞いに対する責務 」とも呼ばれ、その名の通り、特定の振る舞いを提供しなければならない義務を指す。情報把握責務は、「知識に対する責務 」とも呼ばれ、属性や、それを利用して導出できるような情報を把握しておかねばならない義務のことだ。関心の分離で抽出されたソフトウェアコンポーネント は、こうした責務にもとづく複数の振る舞いや知識で構成される。そして、この構成要素間の関係性の強さを、凝集度(cohesion) や強度(strength) と呼び、高いほど良いとされている。
UML の開発に貢献したソフトウェア技術者であるグラディ・ブーチ(Grady Booch)は、凝集度について次のように述べている。ここで「機能的凝集(functional cohesion) 」とは、凝集度のレベルを 7 段階で分類した、最善のレベルのことだ。
high functional cohesion as existing when the elements of a component (such as a class) "all work together to provide some well-bounded behavior"
(高い機能的凝集は、コンポーネント (クラスなど)内の要素が「適切に境界付けられた何らかの振る舞いを提供するために全てが協働する」ときに存在する)
コンポーネント の凝集度が高いと、他のコンポーネント との結合度(coupling) コンポーネント 単体での再利用性(reusability) が高まる。凝集度が高いことが良いとされる理由のひとつは、ここにある。
サービスコ ンポーネントとしての役割にとって、再利用性とは何だろうか。それは、定義したそのままの形で、役割を他の人に交代したり、冗長化 したりできることだ。もちろん、役割を果たすために必要なスキルや知識を保有 していることが前提となる。
もし、役割を交代する時に、役割定義の一部を変更しなければならなかったり、責務の一部だけを引き渡すことになったり、あるいは他の役割とセットにしなければならないようなら、役割の凝集度が低いのだ。役割定義をそのままで再利用できていない。
だから、マネージャーは、再利用性に着目しながら役割の凝集度を上げていく。そこに含まれる実行責務として、プロセス内で必要十分かつ最小限のアクティビティを保有 させる。情報把握責務としては、必要な情報が、必要なタイミングで揃うように、プロセス内での情報の流れにも注意しておきたい。
情報把握責務という点では、データや情報の保存場所も整備すべき対象となる。メンバーが、データや情報を自身のローカル環境にため込んでしまうと、役割の冗長化 がしづらい上に、情報をロストする危険性もある。一時的なデータや情報ならそれでも構わないが、永続化が必要なデータや情報は、メンバー間で共有できる場所に保存する。ソフトウェア開発業務なら、Git のローカルリポジトリ にコミットしたソースコード を、リモートリポジ トリに push する行為などが、これにあたる。ステートレス(stateless) な設計を心掛けよう。
凝集度を最適に設計することは難しい。マネージャーはこのようにして、日々、プロセスを見直しながら役割の定義を洗練させていく。
非同期メッセージング
メッセージキュー を介した非同期メッセージング は、メッセージを生産するプロデューサーと、それを処理するコンシューマーを分離する。プロデューサーは、コンシューマーが過負荷な状態であっても、それを気にすることなくメッセージをキューに追加できる。コンシューマーは、プロデューサーからのメッセージ投入が一時的にスパイクしても、その影響を直接的に受けることはない。例えコンシューマーがダウンしても、メッセージは失われにくく、キューに残ったメッセージで処理を再開できる。プロデューサー、コンシューマーともに、スケールさせやすい。
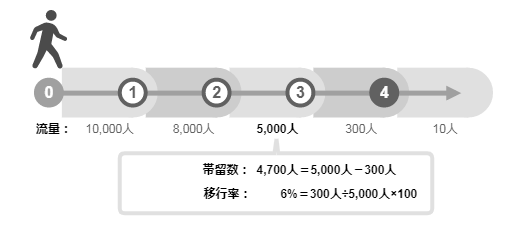
チームが提供するサービスには日々、外部からの依頼が次々と届く。受託開発業務の見積プロセスなら、営業から見積依頼が届けられる。これを、チームメンバーが口頭で受け、そのまま処理するようなプロセスになっているなら問題がある。この方式はマネージャーにとって、依頼のトラフィック 量やチーム内での負荷の偏りが見えにくく、マネジメント不能 な状態に陥りやすい。口頭でのやり取りが行われるシーンをイメージしてみよう。どんな問題が起きるのだろうか。
プロデューサーからの依頼が一時的にスパイクすると、コンシューマー役となるチームメンバーに過負荷を引き起こす。
チーム内に、同じ役割を持つコンシューマー役を複数配置してスケールさせていても、依頼者となるプロデューサーは、依頼先をお気に入りのコンシューマーに偏らせる傾向がある。そして、そういう対象になるコンシューマーは、他のプロデューサーからも人気者だ。だから、一部のメンバーに負荷が偏りやすくなる。
コンシューマー役のメンバーが、依頼を握ったまま体調不良で数日休んでしまうと、マネージャーにもチームにも、その状況がわからなくなる。
プロデューサーからの任意のタイミングでの口頭依頼は、コンシューマー役のコンテキストスイッチ を引き起こす。コンテキストスイッチ は、仕事のオーバーヘッドになり、業務効率を低下させる。
このような状況を生み出さないよう、マネージャーは、プロセス設計を工夫すべきだ。プロセスを開始させるプロデューサーが、コンシューマー役と直接コミュニケーションを取らず、メッセージキューを介すよう設計する。もちろん、全てのプロセスに、メッセージキューを配置できるわけではない。業務効率とのバランスで決める。
メッセージキューとして一番シンプルなものは、メーリングリスト だろう。凝ったものなら、入力フォームからメッセージを登録する方法もある。ITS(Issue Tracking System)といったツールも使える。この場合、窓口役となるメンバーを置いて、依頼者からのメッセージをイシューやチケットに登録しても構わない。
一方、メッセージを受け取る方法は、コンシューマーによるポーリング と、メッセージキューの管理者からコンシューマーへの通知 という、2 つの方法が考えられる。前者は分散型 であり、後者は中央集権型 と言える。どちらが好ましいか一概には言えない。分散型の方が自律的であるが、コンシューマー役が複数人で冗長化 されていると、考慮すべき点が出てくる。キュー内のメッセージは、適切な優先順序で取り出し、重複なく、負荷の偏りがないよう、担当するコンシューマーを決定しなければならない。分散型ではこれを決定する判断基準やルールを、冗長化 された複数のメンバーで共有し、協調して実行することになる。
メッセージのフォーマットも定義しておきたい。プロデューサーごとにばらつきがあると、受け取る側のコンシューマー役が、メッセージを解釈するコストを支払うことになる。不足する情報を確認するために余分なコミュニケーションが発生することもあるだろう。これについては先述した通り、サービスインタフェースの中で定義しておく。
ここではサービス外部からの依頼にフォーカスをあてたが、実際は、担当者をまたぐアクティビティ間のメッセージング(コミュニケーション)はすべて、同じことが言える。例えばコードのレビュー依頼であれば、Github や Gitlab を通してプルリクエス ト(マージリクエス ト)を送り、Github , Gitlab 上でレビューを行うことで、キューとインタフェースを実現すると良いだろう。
役割ベースのマイクロサービスアーキテクチャ としてデザインされたチーム
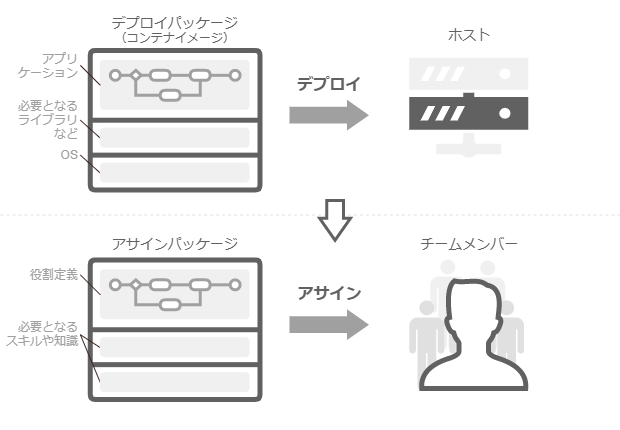
コンテナベースアプリケーション は、アプリケーションも含めたファイルシステム をコンテナイメージ としてパッケージングし、それをホスト 上で、コンテナ に格納して実行する。コンテナは、コンテナイメージをプリミティブとするインスタンス であり、容易にスケールアウトできる。
メンバーを役割にアサイ ンすることは、これに似ている。アサイ ンにおけるプリミティブとは、役割の定義と、それを担うために必要なスキルや知識をパッケージ にした単位だ。メンバーは、このパッケージを単位として役割を担う。同一の役割を複数のメンバーが担うこともあれば、複数の役割を単一のメンバーが担うこともある。
これを、コンテナベースアプリケーションとマッピング するなら、役割はアプリケーションであり、役割に前提となるスキルや知識を合わせたパッケージがコンテナイメージ、メンバーがホスト、といったところか。アサイ ンとは、デプロイのようなものだ。
デプロイとアサイ ン
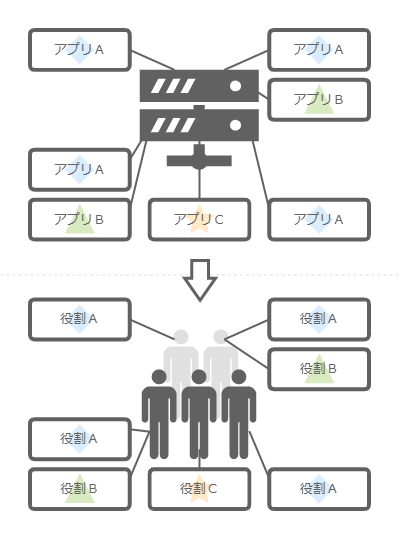
このようにとらえると、チームというものがシステムとして機能しているとよくわかる。そして、役割とはサービスを関心で分離したコンポーネント 、つまりマイクロサービスだと考えると、チームは、役割ベースのマイクロサービスアーキテクチャ としてデザインされたシステムに見えてくる。
役割ベースのマイクロサービスアーキテクチャ
役割のポータビリティ
コンテナイメージの存在は、アプリケーションにポータビリティ(portability) をもたらした。コンテナイメージには、アプリケーションを実行するために必要なライブラリやファイルが全て格納されている。ポータビリティに注意してアプリケーションを設計・実装すれば、コンテナイメージは基本的にどのホストでもコンテナ内での実行が可能だ。ホストに合わせてコンテナイメージをビルドし直したりはしない。これが、システムのスケールや移行を容易にしている。
役割の冗長化 や交代のためにも、ポータビリティは必要となる。役割の凝集度を上げることで再利用性は上がるが、それだけではポータビリティとして不十分だ。役割を担うには、前提となるスキルや知識が必要となる。だから、役割を担う上でどんなスキルや知識を利用するかを明らかにし、役割定義と共にそれらをパッケージングする。そこには、スキル獲得のための教育コンテンツや、知識ベースの整備も伴うだろう。役割にアサイ ンされることになるメンバーは、それらを活用してスキルや知識をインストールし、役割定義を理解した上で、稼働を始める。稼働までのリードタイムは、こういったトレーニン グコストをどれだけ小さくできるかにかかっている。
コンテナイメージはレイヤー化されている。あらたなコンテナイメージをコンテナとして稼働する時、共通のレイヤを重複してストレージに格納する必要がない。こうすることで、軽量化を実現している。
役割をアサイ ンされたメンバーが稼働を始めるまでのリードタイムを縮める方法も、ここにヒントがある。役割に必要とされるスキルや知識をメンバーが既に保有 しているなら、トレーニン グコストを最小化できるからだ。メンバーを新たな役割にアサイ ンする時に、以前に経験したアサイ ンパッケージに含まれるスキルや知識が役立つこともある。ひとりのメンバーに複数の役割を兼任させるケースなら、必要とされるスキルと知識が近い役割をアサイ ンするのも良いだろう。
ポータビリティが下がるケースとして、特定のメンバーが、同じ役割を長期間、担い続けてしまった時が考えられる。このケースでは、役割の属人化が進んでしまう。適度な頻度での役割の振り分け変更は行うべきだろう。
役割に対する権限付与
実行中のアプリケーションが、処理に必要なリソースにアクセスできないと、アクセス違反が発生して処理に失敗してしまう。こうならないために、アプリケーションの実行に必要となるアクセス権限を、ポリシーとしてあらかじめコンテナにアタッチする。
メンバーが責務を果たすためには、アサイ ンされた役割に応じた権限が必要となる。必要十分な権限が付与されないと、アクセス違反が発生してプロセスが止まる。これを都度、マネージャーが処理するようなプロセスであるならば、それは単なるボトルネック だ。人手を介さなければサービスが完結しないシステムのようなもの。チームを信頼し、権限委譲を適切に行う。
ここで注意したいのは、人に対して権限を付与するのではなく、役割に対して権限を付与するということ。つまり、RBAC(role-based access control) だ。それが役割の標準化につながり、ポータビリティや再利用性を高めることにつながる。
単一障害点
単一障害点(single point of failure, SPOF) を残すと、何らかの問題が発生した時に、サービス停止を引き起こしてしまうリスクとなるのは、システムもチームも同じだ。チームなら、メンバーの病欠や、退職などが起こり得る。だから、チーム体制の設計にもフォールトトレランス(fault tolerance) を持ち込む。単一障害点となるような役割があるなら冗長化 可用性(availability) を高めておく。
チームとマネージャーの責任分界点
コンテナオーケストレーション プラットフォーム である Kubernetes アーキテクチャ は、データプレーン とコントロール プレーン に分かれている。データプレーンは、一台以上のワーカーノードのクラスタ ーで、コンテナはここで実行される。一方、コントロール プレーンは、クラスタ ーやコンテナの稼働を正しい状態に維持する役目を担っている。コンテナをノードに割り当てることや、コンテナのレプリカ数を正しく保つこと、ノードがダウンした場合に、コンテナを他のノードに再割り当てすることなどを含んでいる。
このアーキテクチャ は、チームとマネージャーの間にある責任分界点 について示唆に富んでいる。チームは、それぞれのメンバーが役割を果たし、互いに協働することを通して、サービス提供に責任を持つ。一方、マネージャーは、チームがその責任を果たせるよう、チームの稼働、すなわち信頼性(reliability) に責任を持つ。マネージャーは、サービスに対する責任はあるが、サービス提供を実施すること自体は責務ではないということだ。もし、マネージャーがサービス提供も担っているとしたら、それはチームメンバーを兼任している(プレイングマネージャー )のであって、マネージャーの責務として実施している訳ではないだろう。
ビジネスと戦略
「戦略 」と聞いて、エンジニアが真っ先に思い出すのは、GoF の Strategy パターン だろうか。Strategy は、オブジェクトのアルゴリズム デザインパターン だ。
問題を解決するための方法や手順のこと。問題解決の手続きを一般化するもので、プログラミングを作成する基礎となる。アルゴリズム は1つの問題に対し、複数ある場合が多い。(アルゴリズム - 意味・説明・解説 : ASCII.jpデジタル用語辞典 )
例えば「ソート」という問題ひとつをとっても、様々なアルゴリズム が存在する。ソートを行うコンテキストよって、選択すべき最適なアルゴリズム が異なるからだ。
ビジネスにとっての戦略も、ビジネスの振る舞いを決定するアルゴリズム のようなもの。ビジネスにも、とり得る戦略が様々ある。ビジネスを取り巻く内外の環境にあわせ、最適な戦略を選択することが重要だ。そしてその環境は常に変わっていく。だから、戦略は不変ではない。
マネージャーは、自身が担うサービスに組み込むべき戦略を選択・設計し、それをプロセスとして実装する。戦略というアルゴリズム を、チームとして実行できる形にしたものがロジック、つまりはプロセスなのだ。
実のところ、経営における「戦略」という言葉の扱いは曖昧だ。「戦術 」という言葉と使い分けられることもあれば、そうでないこともある。ビジネス現場で戦術という言葉は頻出しないように思うので、ここでは両者を「戦略」として一括りにしている。
Strategy パターンでは、Strategy という抽象クラス(インタフェース)を介し、コンポジション (composition, 合成)アルゴリズム をコードにする。
先述したように、ビジネスにおいて、戦略として選択したアルゴリズム は、プロセスとしてロジック化される。この構造では、サービスごとの戦略(アルゴリズム )を決めるのは、それぞれのサービスを担うマネージャーとなる。実装を委譲されているので、当然だろう。
しかし、注意が必要となるのは、ビジネスにとっての戦略では、サービス定義そのものが変わることがある、という点だろう。Strategy パターンで言えば、Strategy 抽象クラスの定義が変わってしまうことに相当する。これは、実装を委譲された側にとって、大きな影響がある。では、サービス定義が変わってしまうのは、なぜだろうか。
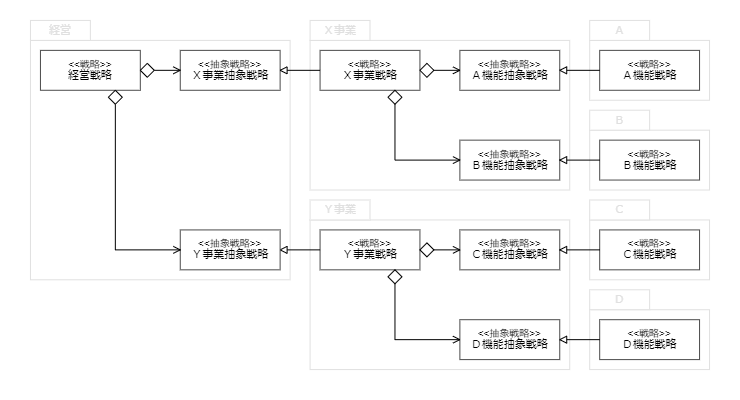
企業では、組織構造上の上位の戦略にもとづいて、下位の戦略が決まる。この時、上位の具象戦略の振る舞いの一部をいくつかの抽象戦略として規定し、下位のサービスに委譲するのだ。つまり、依存性逆転の原則を、Strategy パターンを連鎖させることで実現している。
組織構造と戦略の関係
どこかで見た構造ではないだろうか。これは、サービスの構造と一致している。つまり、サービスの構造は、戦略の構造そのものなのだ。
マネージャーは、上位の戦略変更によって、担当するサービスの業務分掌自体が変更され得ることを理解した上で、チームを運営する。サービス定義の変更は、メンバーからのネガティブな反応を招きやすい。彼らの共感が得られるよう、マネージャー自身が戦略の全体像をしっかり理解し、それをチームに説明する機会を設ける。
ところで戦略は、全社戦略 、事業戦略 、機能戦略 に分類できる。全社戦略はひとつ以上の事業戦略で構成され、事業戦略はひとつ以上の機能戦略で構成される。全てをまとめて経営戦略 と言う。事業がひとつだけの企業なら、全社戦略=事業戦略となる。これが、実際の組織構造にマッピング される。チームのサービスが事業レベルであるなら事業戦略を、機能レベル(開発、セールス、マーケなど)なら機能戦略を担うことになる。
戦略が先か、組織が先か
ここまで、「組織は戦略に従う 」という前提のもとに、チームマネジメントについて考察を進めてきた。しかし実際には、理想的な戦略を作り出せても、それに合った理想的な組織を作り出せることは稀だろう。経営資源 による制約を受けるからだ。特に、人的資源による制約が、組織構造に大きな影響を与える。これは、人数的なものや能力的なものだけではない。新たな戦略や、既存戦略からの変化を、全ての人が共感・歓迎するわけではないからだ。これが、逆の「戦略は組織に従う 」という命題だ。
「組織は戦略に従う」はアルフレッド・チャンドラー 、「戦略は組織に従う」はイゴール・アンゾフ の言葉として有名だ。
これは、どちらか一方が正しいというものではない。どちらも考慮しながら、最終的な戦略、組織に落とし込むのが、現実的な手法なのだろう。
戦略の変更に対するマネージャーの活動内容は、チームへの影響が低い順に次のようなレベルが考えられる。
判断基準やルールの変更
プロセスの変更
サービスの変更
ビジネスの変更
以下に、架空の企業における戦略の変化と、それに追従するプロダクト開発チームへの影響をストーリーにした。このストーリーを追った後に、そこでのマネージャーの活動について考えることにする。
戦略の変化をストーリとして追ってみる
A 社では、10 代の若者をターゲット市場とする自社プロダクトを展開している。このプロダクトはスマホ アプリで、コンセプトが画期的だったこともあり、ローンチから数年は同カテゴリに競合となるようなアプリもほとんどなく、ターゲット市場を独占して大きな収益を出していた。しかし、この状況はここ数年で大きく変わり、同カテゴリに競合となる他社アプリがひしめき合い、ユーザーを奪い合う状態が続いていた。当然ながら収益は徐々に低下していった。
この状態を危惧し、マーケティング チームがアプリの利用状況を詳細に分析したところ、ローンチ当初は 10 代だった層で、現在は 20 代になった層に、アプリのコアファンが多いことが判明した。そこで、ターゲット市場を 10 代に加え、 20 代にも拡大することで、新たなユーザーを獲得する戦略を立てた。
アプリの開発業務を担うチームでは、ユーザーからの要望リストを持っている。これまでは 10 代向けの要望対応に開発リソースの多くを投下してきた。新戦略ではこの優先順位付けの基準を変更し、 20 代向けの要望対応に開発リソースを集中投下することにした(1. 判断基準やルールの変更)。
A 社では、比較的大きな単位で機能を開発し、ローンチする戦略を取っていた。それが、ターゲット市場に対するマーケティング 面でのインパク トになるし、必要となる機能を一通り揃えてローンチすることが、ユーザーにとっての価値・利便性にもつながると考えていたからだ。そのため、企画からローンチまでにおよそ半年程度の期間を要していた。しかし、過当競争にある 10 代向け市場では、競合他社が次々と新たな機能を出してくる。このような外部環境の変化が、開発中の機能に対する仕様変更を引き起こすことが多くなってきた。これがプロジェクトを後戻りさせ、ローンチを延期させることに繋がり、開発期間はますます長くなっていった。
開発チームは、この開発効率性悪化の原因を、開発プロセス モデルが競争面でミスマッチを起こしているからだと考えた。これまで、マーケティング 部門から受け取った機能企画を、ウォーターフォール 型のプロセスモデル で開発していたが、スクラム 開発に切り替え、短期間で小さな機能単位のローンチを繰り返すことで、ターゲット市場の変化に対応しやすい体制を組んだ(2. プロセスの変更)。
スクラム 開発も上手く機能し、外部環境の変化へも柔軟に適応できるようになった。この成功を更に加速させるため、プロダクト企画チームメンバーを、プロダクト開発チームに異動させ、企画と開発を一体化したスクラム 開発体制を組むことにした(3. サービスの変更)。
アプリは順調にユーザーを増やしていき、収益も向上していった。プロモーション担当チームの活躍により、メディアで取り上げられることも多くなった。これに目を付けた大手インターネット企業からスマホ アプリ事業の買収が打診され、会社ごと吸収合併されることになった(4. ビジネスの変更)。
ストーリーの中でマネージャーがとる行動
ストーリー中の(1)は、マーケティング戦略 変更に伴うプロダクト戦略の変更であるが、その影響は意外に小さかった。要望対応リスト内のアイテムに対する優先順位付けの基準を変更しただけだ。プロセスは大抵、このようなリスト(キュー)を抱えており、そのアイテムどのような順番で処理するかは、スケジューリング方針次第だ。単純に、FIFO (first in, first out) であれば良いというものではない。どういう仕事に対してリソースを優先的に投下するかの決定は、重要な判断だ。チームがこの判断を自ら行えるよう、新たなスケジューリング方針を定義することが、ここでのマネージャーの仕事であった。
(2)では、プロダクト戦略自体に変更はなかったが、開発プロセス との相性が悪かった。そのため、開発プロセス モデルをウォーターフォール からスクラム に変更している。サービスインタフェースへの影響はなさそうだが、プロセスの変更は、役割定義に影響をおよぼす。これは、チーム構造が変わることを意味する。変更の背景と目的を、チームメンバーにしっかりと説明し、理解を得ておく。
(3)では、互いにプロダクト戦略を担っていたプロダクト企画業務とプロダクト開発業務を一体化した。業務分掌に対して機能を追加することになるため、チームが提供するサービスの範囲が拡大する。サービス定義の変更は、サービスインタフェース、プロセス、チーム構造すべてに変化を要求する。こういうケースは現状からの変化が大きすぎ、チーム内で「それはうちの仕事じゃない」といったネガティブな反応を起こしやすい。それどころか、マネージャー自身が、同様の拒否反応を示すようなこともしばしば見られる。これはきっと、マネージャーが石切り工の「第二の男」でとどまっているのだろう。まずは、戦略に対してマネージャー自身が腹落ちすることが重要だ。
(4)は、吸収合併によって、そもそも事業戦略から見直すことになった。組織構造も大きく変わるだろう。新たな組織の中で、マネージャーという役割を担い続けることになるのかもわからない。それでも、この大変化を成功させるために、現組織のマネージャーとしてリーダーシップを発揮しながら、新たな組織作りを推進していく。
目標とモニタリング
モニタリングは目標への道標
書籍『「SRE サイトリライアビリティエンジニアリング ―Googleの信頼性を支えるエンジニアリングチーム 」Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy 著、オライリージャパン (2012)』では、モニタリング について次のように述べられている(引用はオンライン英語版より )。
Without monitoring, you have no way to tell whether the service is even working; absent a thoughtfully designed monitoring infrastructure, you’re flying blind.
(モニタリングがなければ、サービスが稼働しているかどうかを知る方法はない。思慮深くデザインされたモニタリング基盤がなければ、目隠しで飛行しているようなものだ。)
マネジメント活動にとってもモニタリングは判断の道標となる。モニタリングがなければ、サービスの状況を知ることが困難となる。問題に気づかないようなことは避けたい。サービス品質が低下すると、サービスを利用する他チームのサービス品質を低下させてしまう。サービス利用者がお客様なら、サービスに対する満足度の低下を招く。
道標と言うからには、到達しようとする目標がある。目標と現在地のギャップが、進むべき方向になるというわけだ。マネージャーは、目標を立てたら道標を頼りにチームが乗るバスを走らせていく。モニタリングによって問題を検知し、判断し、対応することを繰り返していく。
このモニタリングと目標に関する活動は、以下に述べる「サービス」「プロセス」「チーム」「ビジネス」の 4 つに分類して進めることになる。
サービスの目標とモニタリング
エンジニアリング活動で、サービスに関するモニタリングは症状指向(symptom-oriented) だ。サービス利用者に対し、既に影響を与えている症状を検知するものだからだ。当然ながら、エンジニアによる問題への対応はリアクティブにならざるを得ない。しかし、だからこそ緊急度の高い問題を検知するために必要な仕組みとなる。SRE ではこれを、ブラックボックスモニタリング(black-box monitoring)
稼働中のシステムが提供するサービスの品質評価には、SLA SLI , SLO を使う。
SLA (Service Level Agreement, サービスレベル合意)SLI(Service Level Indicator) :SLA を履行するために監視すべき、サーバーやネットワーク、ストレージなどに関する定量 的な測定項目。SLO(Service Level Objective) :SLI に対する目標値やその範囲。
SLA や SLO を継続的に満たすよう、エンジニアは日々、目標と実績のギャップに注目しながらシステムを運用していく。
マネジメント活動で、チームが提供するサービス水準を取り決めるケースはあまり聞かない。しかし、SLA , SLO を目標として定義しておくことは、サービス品質に良い影響を与えるだろう。
指標の対象となるのは、サービスインタフェースに規定されている振る舞い(主に利用者からの入力、あるいは利用者への出力に関わる振る舞い)のレイテンシやスループット 、エラー状況などだ。提供しているサービスがプロダクト開発業務なら、開発期間や単位期間内のデリバリー回数、障害発生件数などが考えられる。
サービス品質に対する期待値コントロール もマネージャーの務めだ。サービス利用者や関係者の期待値が過剰になると、SLA や SLO を満たしていても、彼らはサービス品質に不満を持つようになる。例えば、サービスが定常的に目標値を上回る品質を継続していたとしよう。すると、サービス利用者や関係者にとってそれが当たり前になり、期待値が上がってしまう。あるいは、目標値の定義にあいまいな表現が含まれていたために、サービス利用者や関係者との間に認識の齟齬が生まれるようなケースもある。だから、マネージャーは利用者や関係者の期待値レベルも、モニタリングすべきだろう。
可能であれば、サービス品質について、サービス利用者に聞いてみる。定期的に実施するのが良いだろう。その方法として、NPS(Net Promoter Score, ネットプロモータースコア) を利用したアンケートが考えられる。NPS は、顧客や利用者のサービス継続利用意向を知るために、アンケート回答者を「推奨者(Promoter)」「中立者(Passive)」「批判者(Detractor)」に分類する指標だ。アンケート項目も最小限で、回答者への負荷も小さい。
プロセスの目標とモニタリング
ブラックボックス モニタリングに対し、システム内部のメトリクスに基づくモニタリングを、SRE ではホワイトボックスモニタリング(white-box monitoring)
ホワイトボックスモニタリングは基本的に原因指向(cause-oriented) だ。症状として表出した問題の原因を特定可能にする。また、症状として表出していない問題を検知するケースもあり、プロアクティブ な対応も可能にする。プロビジョニングを計画するための情報源としても利用できる。
プロセスに対するモニタリングでは、このホワイトボックスモニタリングを行うことになる。指標に対して目標値や基準値を設けることは言うまでもない。
プロセスのモニタリングで指標として考えられるメトリクスは、プロセス単位、アクティビティ単位でのスループット やレイテンシー あたりだろう。もし、設定された目標や基準値を満たせないことが続くようなら、プロセスの設計・実装を見直すことを考える。リファクタリング によって業務効率向上が期待できる。プロセスやアクティビティの一部は、可能なら自動化してしまう。
エラーの頻度も、プロセス品質を評価する指標として使える。もし、プロセス内の特定の個所でエラーが頻発しているなら、例外処理をプロセスに組み込み、チーム内での解決を可能にする。例外が発生するたびにアラートを投げてマネージャーが処理するのは効率が悪い。
チームの目標とモニタリング
チームのモニタリングも、プロセスのモニタリングと同じようにホワイトボックスモニタリングとなる。指標として活用できそうなメトリクスは様々考えられるが、ここでの目標値や基準値は、チーム体制、人員計画、育成計画、開発計画、製造原価・販管費 予算といった計画にリンクさせて管理するのが良いだろう。
チーム体制、人員計画に関係する指標には、チーム全体や個々のメンバーの「残業時間が適切な範囲に収まっているか」「休暇の取得状況が通常レベルであるか」「特定のメンバーに負荷が偏っていないか」といったものがある。これらが適正な範囲にないようなら、チーム内の負荷分散や冗長構成についてチーム体制を見直すことになるだろう。人的リソースの調達は、可能な限り人員計画に沿って進めたい。メンバーのトレーニン グや育成によって、計画的にチームパフォーマンスを向上させることも怠らないようにする。
人的リソースを調達するなら、配置換え、社内異動、採用(新卒、中途、パート・アルバイト)、労働者派遣、業務委託(準委任、請負)といった方法から、状況に応じて最適なものを選択する。
開発計画に関係する指標としては、チームが投下した「製造原価工数 」をみておきたい。実績が計画から乖離しすぎてはいけない。
製造原価・販管費 予算に対しては、「勤務時間に対する製造原価工数 の割合は適切な範囲にあるか」を見る。この割合が低すぎるなら、チームがシステム開発 業務に専念できていない可能性がある。割合が適正であっても、「製造原価工数 に対するソフトウェア保守工数 は適切な範囲にあるか」を見ることで、その内容が妥当であるかどうかを判断できる。スマホ アプリや SaaS のようなプロダクト開発業務なら、顧客価値の高い機能追加に対して、可能な限り多くの製造原価工数 を割り当てたい。場合にもよるが、保守工数 の比率が高すぎるなら、何らかの問題を抱えていることを疑う。
チームのヘルスチェック
Google は、Project Aristotle(プロジェクトアリストテレス ) において、「効果的なチームを可能とする条件は何か」という問いに対し、最も重要な因子は「心理的安全性 」だと突き止めた 。心理的安全性 とは、対人関係においてリスクある行動を取ったときの結果に対する個人の認知の仕方、つまり、「無知、無能、ネガティブ、邪魔だと思われる可能性のある行動をしても、このチームなら大丈夫だ」と信じられるかどうかを意味する。
このことから、高い心理的 安全性を作り出すことが、マネジメント活動の重要な要素だとよくわかる。チームの心理的 安全性がどの程度のレベルであるかは、チームメンバーに、次のように質問する ことで把握できる。これを、アンケートの設問として活用し、チームの状態を定点観測してみてはどうだろうか。
チームの中でミスをすると、たいてい非難される。
チームのメンバーは、課題や難しい問題を指摘し合える。
チームのメンバーは、自分と異なるということを理由に他者を拒絶することがある。
チームに対してリスクのある行動をしても安全である。
チームの他のメンバーに助けを求めることは難しい。
チームメンバーは誰も、自分の仕事を意図的におとしめるような行動をしない。
チームメンバーと仕事をするとき、自分のスキルと才能が尊重され、活かされていると感じる。
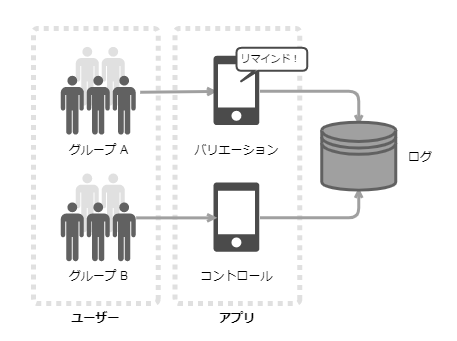
また、心理的 安全性をチーム文化として定着させるために、分報(times) 心理的 障壁が下がる。チャンネルが公開されているので、誰かが困っている様子も可視化され、チームで助け合える。
マネージャーにとって分報は、チームの様子をリアルタイムでモニタリング可能なログ としても使える。メンバーが課題や不満、不安などを抱えている様子が見えたなら、その都度、1on1 などを通して話を聞き、対応する。
チームの成長段階と DX の関係
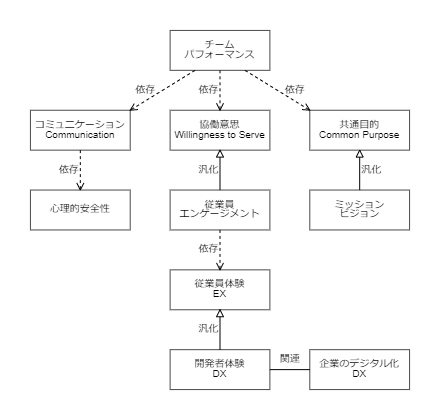
チェスター・バーナードの、組織が成立する 3 つの条件である「共通目的」「コミュニケーション」「協働意思」は、チームに最初から備わっている訳ではない。タックマンモデル(Tuckman's stages of group development)
チームの「共通目的」とは、「ミッション」や「ビジョン」だと述べた。「コミュニケーション」は、「心理的 安全性」によって活性化する。「協働意思」については、ここまで触れてこなかったが、メンバーの「従業員エンゲージメント 」を引き上げることによって得られると考えている。ウイリス・タワーズワトソンの定義 では、従業員エンゲージメントとは「会社・組織が成功するために、従業員が自らの力を発揮しようとする状態が存在していること」とされ、企業のパフォーマンスへの影響度を測る上で、「コミットメント」より先進的な概念とされている。
2012 年に行われた Gallup の調査 では、従業員エンゲージメントの高さで上位 4 分の 1 に入るワークユニットは、下位 4 分の 1 のユニットに対し、顧客評価で 10%, 収益性で 22%, 生産性で 21% 上回った。また、離職率 は 25% ~ 65%、欠勤は 37%, 品質上の欠陥は 41% 下回った。
ここで、ワークユニットごとの従業員エンゲージメントは、Gallup が独自に開発した設問に対する従業員からの回答をもとに計測されている。その内容(サンプル 、日本語記事 )を見ると、従業員体験(employee experience, EX) が深く関わっていることがわかる。
Q00 - How satisfied are you with [Company Name] as a place to work? / 働き場所として、会社にどれほど満足しているか
Q01 - I know what is expected of me at work. / 職場で自分が何を期待されているのかを知っている
Q02 - I have the materials and equipment I need to do my work right. / 仕事をうまく行うために必要な材料や道具を与えられている
Q03 - At work, I have the opportunity to do what I do best every day. / 職場で最も得意なことをする機会を毎日与えられている
Q04 - In the last seven days, I have received recognition or praise for doing good work. / この7日間のうちに、よい仕事をしたと認められたり、褒められたりした
Q05 - My supervisor, or someone at work, seems to care about me as a person. / 上司または職場の誰かが、自分をひとりの人間として気にかけてくれているようだ
Q06 - There is someone at work who encourages my development. / 職場の誰かが自分の成長を促してくれる
Q07 - At work, my opinions seem to count. / 職場で自分の意見が尊重されているようだ
Q08 - The mission or purpose of my company makes me feel my job is important. / 会社の使命や目的が、自分の仕事は重要だと感じさせてくれる
Qv9 - My associates or fellow employees are committed to doing quality work. / 職場の同僚が真剣に質の高い仕事をしようとしている
Q10 - I have a best friend at work. / 職場に親友がいるQ11 - In the last six months, someone at work has talked to me about progress. / この6カ月のうちに、職場の誰かが自分の進歩について話してくれた
Q12 - This last year, I have had opportunities at work to learn and grow. / この1年のうちに、仕事について学び、成長する機会があった
従業員体験の対象をエンジニアに絞れば、開発者体験(developer experience, DX) になる。そして、DX と言えばもうひとつ、企業のデジタル化(Digital Transformation, DX) もある。日本CTO協会ではこの 2 つの DX を一体として捉えるべきだと説いている 。
一つは、企業がどれだけ経営に対してデジタル技術を用いたビジネス変革ができているかを表す企業のデジタル化(Digital Transformation)です。
もう一つは先端開発者にとっての働きやすい環境と高速な開発を実現するための文化・組織・システムが実現されているかを意味する開発者体験(Developer eXperience)です。
これらの2つは、経営にとってヒト・モノ・カネが一体であるように、一体で実現されるものです。デジタル技術は目に見えないため、しばしばわかりやすいものにだけ投資して見えない品質をおろそかにしてしまいます。そのため、開発者体験は悪化し、企業のデジタル化を阻害してしまうことがあるのです。
チーム(組織)の DX を診断するには、同協会が提供する DX Criteria を使う
「コミュニケーション」「協働意思」「共通目的」はそれぞれ、心理的 安全性の向上、DX 向上、ビジョンミッションの浸透によって高められる。タックマンモデルで、チームが最大のパフォーマンスを発揮する段階である「機能期(Performing) 」への到達は、これら 3 つ全てを高いレベルに引き上げてようやく実現できるのだ。
チームパフォーマンス
ビジネスの目標とモニタリング
多くの企業は事業に対し、半期や通期(一年間)ごとに目標 を決める。そして、目標達成に向けた活動を計画し、期末にその結果を評価する。ここで使われる指標が KGI , KSF , KPI だ。
KGI(Key Goal Indicator, 重要目標評価指標) :経営戦略や事業戦略の達成度合いを評価するための測定項目と目標値のセット。KSF(Key Success Factor, 重要成功要因) :KGI を達成するために重要となる要因を評価するための測定項目。KPI(Key Performance Indecator, 重要業績評価指標) :KSF の進捗度合いを評価するための測定項目と目標値のセット。
ここでも E コマース事業を例にすると理解しやすい。目標を「顧客数を拡大して売上 1,000 万円アップ」と定義したと想定する。つまり、KGI は「売上 1,000 万円アップ」、KSF は「顧客数」だ。現在の顧客単価が 1 万円だとすると、顧客数を 1,000 人増やさなければならない。考えられる KPI は、「オンライン広告からの流入 数を〇〇人増やす」や、「既存顧客からの紹介率を〇〇%上げる」などだ。
KGI, KPI を定めたら、次はそれを月次レベルでの目標値とアクションプランに落とし込み、これを計画として策定する。あとは、実績をモニタリングしながら、計画とのギャップを確認し、目標の達成に向けて軌道修正を繰り返す。その内容は、チームや関係者に対して定期的に共有・報告する。当然ながら、モニタリング可能となるよう、指標を計測できる仕組みを入れることも忘れてはいけない。
SaaS プロダクト開発業務であれば、機能単位での利用状況や、アクティブユーザー数などが、指標として考えられる。売上や粗利、営業利益を設定するケースもあるが、直接的に事業を担っているチームでない限り、活動が実績値に影響を与えにくい。これでは目標に対するメンバーのコミットメントを得にくいだろう。
目標とは別に、製造原価と販管費 に関する計画を立てることも多い。「チームの目標とモニタリング」でも製造原価について話したが、その視点は工数 であった。ビジネスの目標ではこれを、金額(労務 費、材料費、経費)として扱う。
メンバーの個人目標も、チームの目標やアクションプランを更にブレイクダウンしたものになるだろう。こちらも定期的に 1on1 などを実施し、個人目標に対する進捗を確認する。
なお、最近では目標設定に OKR(Objectives and Key Results)
最後に
本ブログエントリーでは、チームマネジメントをエンジニアリングと比較しながら、チームのアーキテクチャ ・構造を辿り、そこにマネージャーの活動をプロットしてきた。チームとは、抽象としてのサービス、その実装としてのプロセスや役割、そして、それらをアプリケーションとして動作させるプラットフォームとしてのチームメンバーから構成されていた。
チームマネジメントとは、チームアーキテクトたるマネージャーの、エンジニアリング活動だ。そこには、マネージャーが、エンジニアリング経験で得てきたスキルや知識を活用できるポイントがいくつもある。
チームマネジメントとエンジニアリングの大きな違いは、前者がマシンではなく人を対象にしている点だろう。個々のメンバーの特性は均一ではない。興味も違うし、成長もする。日々、コンディションも変わる。だから、安定的で持続性のあるサービス提供を実現するには、プロセスや役割の設計・実装による標準化が鍵を握ってくる。
しかし一方で、行き過ぎた標準化は、サービスを平均的なレベルにとどめてしまう。それでは競争力がない。メンバーにとっても、標準化され過ぎた仕事は面白くないだろう。だから、メンバーそれぞれの興味や強みを生かしたいと思う。だが、それではチームに単一障害点を作ってしまいかねない……
これらのバランスを、どのようにチームデザインに落とし込むのか。マネージャーとしての能力やセンスが求められる。
ここに書いたマネージャーの仕事の多くは、チームやメンバーが担うことも可能なはず。彼らへの権限委譲を進めることで、チームは進化し、自己組織化していく。こうやって、チームマネジメントという役割を蒸留しつつ、最後に残る責務こそ、マネージャーの存在価値たる仕事になるのだろう。